Glottochronology (from Attic Greek γλῶττα tongue, language and χρόνος time) is the part of lexicostatistics which involves comparative linguistics and deals with the chronological relationship between languages.[1]: 131
The idea was developed by Morris Swadesh in the 1950s in his article on Salish internal relationships.[2] He developed the idea under two assumptions: there indeed exists a relatively stable basic vocabulary (referred to as Swadesh lists) in all languages of the world; and, any replacements happen in a way analogous to radioactive decay in a constant percentage per time elapsed. Using mathematics and statistics, Swadesh developed an equation to determine when languages separated and give an approximate time of when the separation occurred. His methods aimed to aid linguistic anthropologists by giving them a definitive way to determine a separation date between two languages. The formula provides an approximate number of centuries since two languages were supposed to have separated from a singular common ancestor. His methods also purported to provide information on when ancient languages may have existed.[3]
Despite multiple studies and literature containing the information of glottochronology, it is not widely used today and is surrounded with controversy.[3] Glottochronology tracks language separation from thousands of years ago but many linguists are skeptical of the concept because it is more of a 'probability' rather than a 'certainty.' On the other hand, some linguists may say that glottochronology is gaining traction because of its relatedness to archaeological dates. Glottochronology is not as accurate as archaeological data, but some linguists still believe that it can provide a solid estimate.[4]
Over time many different extensions of the Swadesh method evolved; however, Swadesh's original method is so well known that 'glottochronology' is usually associated with him.[1]: 133 [5]
Methodology
Word list
The original method of glottochronology presumed that the core vocabulary of a language is replaced at a constant (or constant average) rate across all languages and cultures and so can be used to measure the passage of time. The process makes use of a list of lexical terms and morphemes which are similar to multiple languages.
Lists were compiled by Morris Swadesh and assumed to be resistant against borrowing (originally designed in 1952 as a list of 200 items, but the refined 100-word list in Swadesh (1955)[6] is much more common among modern day linguists). The core vocabulary was designed to encompass concepts common to every human language such as personal pronouns, body parts, heavenly bodies and living beings, verbs of basic actions, numerals, basic adjectives, kin terms, and natural occurrences and events.[7] Through a basic word list, one eliminates concepts that are specific to a particular culture or time period. It has been found through differentiating word lists that the ideal is really impossible and that the meaning set may need to be tailored to the languages being compared. Word lists are not homogenous throughout studies and they are often changed and designed to suit both languages being studied. Linguists find that it is difficult to find a word list where all words used are culturally unbiased.[8] Many alternative word lists have been compiled by other linguists and often use fewer meaning slots.
The percentage of cognates (words with a common origin) in the word lists is then measured. The larger the percentage of cognates, the more recently the two languages being compared are presumed to have separated.
Below is an example of a basic word list composed of basic Turkish words and their English translations.[9]
| hep (all) | ateş (fire) | boyun (neck) | bu (that) |
| kül (ashes) | balık (fish) | yeni (new) | şu (this) |
| kabuk (bark) | uçmak (fly) | gece (night) | sen (thou) |
| karın (belly) | ayak (foot) | burun (nose) | dil (tongue) |
| büyük (big) | vermek (give) | bir (one) | diş (tooth) |
| kuş (bird) | iyi (good) | kişi (person) | ağaç (tree) |
| ısırmak (bite) | yeşil (green) | yağmur (rain) | iki (two) |
| kara (black) | saç (hair) | kızıl (red) | yürümek (walk) |
| kan (blood) | el (hand) | yol (road) | sıcak (warm) |
| kemik (bone) | baş (head) | kök (root) | su (water) |
| yakmak (burn) | duymak (hear) | kum (sand) | biz (we) |
| bulut (cloud) | gönül (heart) | demek (say) | ne (what) |
| soğuk (cold) | ben (I) | görmek (see) | beyaz (white) |
| gelmek (come) | öldürmek (kill) | tohum (seed) | kim (who) |
| ölmek (die) | bilmek (know) | oturmak (sit) | kadın (woman) |
| köpek (dog) | yaprak (leaf) | deri (skin) | sarı (yellow) |
| içmek (drink) | yalan (lie) | uyumak (sleep) | uzun (long) |
| kuru (dry) | ciğer (liver) | küçük (small) | yok (not) |
| kulak (ear) | bit (louse) | duman (smoke) | göğüş (breast) |
| yer (earth) | erkek (man-male) | ayaktakalmak (stand) | hayvan tırnagı (claw) |
| yemek (eat) | çok (many) | yıldız (star) | dolu (full) |
| yumurta (egg) | et (meat-flesh) | taş (stone) | boynuz (horn) |
| göz (eye) | dağ (mountain) | güneş (sun) | diz (knee) |
| yağ (fat-grease) | ağız (mouth) | yüzmek (swim) | ay (moon) |
| tüy (feather) | isim (name) | kuyruk (tail) | yuvarlak (round) |
Glottochronologic constant
Determining word lists rely on morpheme decay or change in vocabulary. Morpheme decay must stay at a constant rate for glottochronology to be applied to a language. This leads to a critique of the glottochronologic formula because some linguists argue that the morpheme decay rate is not guaranteed to stay the same throughout history.[8]
American Linguist Robert Lees obtained a value for the "glottochronological constant" (r) of words by considering the known changes in 13 pairs of languages using the 200 word list. He obtained a value of 0.805 ± 0.0176 with 90% confidence. For his 100-word list Swadesh obtained a value of 0.86, the higher value reflecting the elimination of semantically unstable words. The constant is related to the retention rate of words by the following formula:

L is the rate of replacement, ln represents the natural logarithm and r is the glottochronological constant.
Divergence time
The basic formula of glottochronology in its shortest form is this:

t = a given period of time from one stage of the language to another (measured in millennia),[10] c = proportion of wordlist items retained at the end of that period and L = rate of replacement for that word list.
One can also therefore formulate:

By testing historically verifiable cases in which t is known by nonlinguistic data (such as the approximate distance from Classical Latin to modern Romance languages), Swadesh arrived at the empirical value of approximately 0.14 for L, which means that the rate of replacement constitutes around 14 words from the 100-wordlist per millennium.
Results
Glottochronology was found to work in the case of Indo-European, accounting for 87% of the variance. It is also postulated to work for Afro-Asiatic (Fleming 1973), Chinese (Munro 1978) and Amerind (Stark 1973; Baumhoff and Olmsted 1963). For Amerind, correlations have been obtained with radiocarbon dating and blood groups[dubious ] as well as archaeology.[citation needed]
The approach of Gray and Atkinson,[11] as they state, has nothing to do with "glottochronology".
Discussion
The concept of language change is old, and its history is reviewed in Hymes (1973) and Wells (1973). In some sense, glottochronology is a reconstruction of history and can often be closely related to archaeology. Many linguistic studies find the success of glottochronology to be found alongside archaeological data.[4] Glottochronology itself dates back to the mid-20th century.[6][12][7] An introduction to the subject is given in Embleton (1986)[13] and in McMahon and McMahon (2005).[14]
Glottochronology has been controversial ever since, partly because of issues of accuracy but also because of the question of whether its basis is sound (for example, Bergsland 1958; Bergsland and Vogt 1962; Fodor 1961; Chrétien 1962; Guy 1980). The concerns have been addressed by Dobson et al. (1972), Dyen (1973)[15] and Kruskal, Dyen and Black (1973).[16] The assumption of a single-word replacement rate can distort the divergence-time estimate when borrowed words are included (Thomason and Kaufman 1988).
An overview of recent arguments can be obtained from the papers of a conference held at the McDonald Institute in 2000.[17] The presentations vary from "Why linguists don't do dates" to the one by Starostin discussed above.[clarification needed] Since its original inception, glottochronology has been rejected by many linguists, mostly Indo-Europeanists of the school of the traditional comparative method. Criticisms have been answered in particular around three points of discussion:
- Criticism levelled against the higher stability of lexemes in Swadesh lists alone (Haarmann 1990) misses the point because a certain amount of losses only enables the computations (Sankoff 1970). The non-homogeneity of word lists often leads to lack of understanding between linguists. Linguists also have difficulties finding a completely unbiased list of basic cultural words. it can take a long time for linguists to find a viable word list which can take several test lists to find a usable list.[8]
- Traditional glottochronology presumes that language changes at a stable rate.
- Thus, in Bergsland & Vogt (1962), the authors make an impressive demonstration, on the basis of actual language data verifiable by extralinguistic sources, that the "rate of change" for Icelandic constituted around 4% per millennium, but for closely connected Riksmal (Literary Norwegian), it would amount to as much as 20% (Swadesh's proposed "constant rate" was supposed to be around 14% per millennium).
- That and several other similar examples effectively proved that Swadesh's formula would not work on all available material, which is a serious accusation since evidence that can be used to "calibrate" the meaning of L (language history recorded during prolonged periods of time) is not overwhelmingly large in the first place.
- It is highly likely that the chance of replacement is different for every word or feature ("each word has its own history", among hundreds of other sources:[18]).
- That global assumption has been modified and downgraded to single words, even in single languages, in many newer attempts (see below).
- There is a lack of understanding of Swadesh's mathematical/statistical methods. Some linguists reject the methods in full because the statistics lead to 'probabilities' when linguists trust 'certainties' more.[8]
- A serious argument is that language change arises from socio-historical events that are, of course, unforeseeable and, therefore, uncomputable.
- New methods developed by Gray & Atkinson are claimed to avoid those issues but are still seen as controversial, primarily since they often produce results that are incompatible with known data and because of additional methodological issues.
Modifications
Somewhere in between the original concept of Swadesh and the rejection of glottochronology in its entirety lies the idea that glottochronology as a formal method of linguistic analysis becomes valid with the help of several important modifications. Thus, inhomogeneities in the replacement rate were dealt with by Van der Merwe (1966)[8] by splitting the word list into classes each with their own rate, while Dyen, James and Cole (1967)[19] allowed each meaning to have its own rate. Simultaneous estimation of divergence time and replacement rate was studied by Kruskal, Dyen and Black.[16]
Brainard (1970) allowed for chance cognation, and drift effects were introduced by Gleason (1959). Sankoff (1973) suggested introducing a borrowing parameter and allowed synonyms.
A combination of the various improvements is given in Sankoff's "Fully Parameterised Lexicostatistics". In 1972, Sankoff in a biological context developed a model of genetic divergence of populations. Embleton (1981) derives a simplified version of that in a linguistic context. She carries out a number of simulations using this which are shown to give good results.
Improvements in statistical methodology related to a completely different branch of science, phylogenetics; the study of changes in DNA over time sparked a recent renewed interest. The new methods are more robust than the earlier ones because they calibrate points on the tree with known historical events and smooth the rates of change across them. As such, they no longer require the assumption of a constant rate of change (Gray & Atkinson 2003).
Starostin's method
Another attempt to introduce such modifications was performed by the Russian linguist Sergei Starostin, who had proposed the following:
- Systematic loanwords, borrowed from one language into another, are a disruptive factor and must be eliminated from the calculations; the one thing that really matters is the "native" replacement of items by items from the same language. The failure to notice that factor was a major reason in Swadesh's original estimation of the replacement rate at under 14 words from the 100-wordlist per millennium, but the real rate is much slower (around 5 or 6). Introducing that correction effectively cancels out the "Bergsland & Vogt" argument since a thorough analysis of the Riksmal data shows that its basic wordlist includes about 15 to 16 borrowings from other Germanic languages (mostly Danish), and the exclusion of those elements from the calculations brings the rate down to the expected rate of 5 to 6 "native" replacements per millennium.
- The rate of change is not really constant but depends on the time period during which the word has existed in the language (the chance of lexeme X being replaced by lexeme Y increases in direct proportion to the time elapsed, the so-called "aging of words" is empirically understood as gradual "erosion" of the word's primary meaning under the weight of acquired secondary ones).
- Individual items on the 100 word-list have different stability rates (for instance, the word "I" generally has a much lower chance of being replaced than the word "yellow").
The resulting formula, taking into account both the time dependence and the individual stability quotients, looks as follows:

In that formula, −Lc reflects the gradual slowing down of the replacement process because of different individual rates since the least stable elements are the first and the quickest to be replaced, and the square root represents the reverse trend, the acceleration of replacement as items in the original wordlist "age" and become more prone to shifting their meaning. This formula is obviously more complicated than Swadesh's original one, but, it yields, as shown by Starostin, more credible results than the former and more or less agrees with all the cases of language separation that can be confirmed by historical knowledge. On the other hand, it shows that glottochronology can really be used only as a serious scientific tool on language families whose historical phonology has been meticulously elaborated (at least to the point of being able to distinguish between cognates and loanwords clearly).
Time-depth estimation
The McDonald Institute hosted a conference on the issue of time-depth estimation in 2000. The published papers[17] give an idea of the views on glottochronology at that time. They vary from "Why linguists don't do dates" to the one by Starostin discussed above. Note that in the referenced Gray and Atkinson paper, they hold that their methods cannot be called "glottochronology" by confining this term to its original method.
See also
- Basic English
- Cognate
- Dolgopolsky list
- Historical linguistics
- Indo-European studies
- Leipzig–Jakarta list
- Lexicostatistics
- Mass lexical comparison
- Proto-language
- Quantitative comparative linguistics
- Swadesh list
References
- Dyen, I., James, A. T., & J. W. L. Cole 1967 "Language divergence and estimated word retention rate", <Language 43: 150--171
Bibliography
- Arndt, Walter W. (1959). The performance of glottochronology in Germanic. Language, 35, 180–192.
- Bergsland, Knut; & Vogt, Hans. (1962). On the validity of glottochronology. Current Anthropology, 3, 115–153.
- Brainerd, Barron (1970). A Stochastic Process related to Language Change. Journal of Applied Probability 7, 69–78.
- Callaghan, Catherine A. (1991). Utian and the Swadesh list. In J. E. Redden (Ed.), Papers for the American Indian language conference, held at the University of California, Santa Cruz, July and August, 1991 (pp. 218–237). Occasional papers on linguistics (No. 16). Carbondale: Department of Linguistics, Southern Illinois University.
- Campbell, Lyle. (1998). Historical Linguistics; An Introduction [Chapter 6.5]. Edinburgh: Edinburgh University Press. ISBN 0-7486-0775-7.
- Chretien, Douglas (1962). The Mathematical Models of Glottochronology. Language 38, 11–37.
- Crowley, Terry (1997). An introduction to historical linguistics. 3rd ed. Auckland: Oxford Univ. Press. pp. 171–193.
- Dyen, Isidore (1965). "A Lexicostatistical classification of the Austronesian languages." International Journal of American Linguistics, Memoir 19.
- Gray, R.D. & Atkinson, Q.D. (2003): "Language-tree divergence times support the Anatolian theory of Indo-European origin." Nature 426-435-439.
- Gudschinsky, Sarah. (1956). The ABC's of lexicostatistics (glottochronology). Word, 12, 175–210.
- Haarmann, Harald. (1990). "Basic vocabulary and language contacts; the disillusion of glottochronology. In Indogermanische Forschungen 95:7ff.
- Hockett, Charles F. (1958). A course in modern linguistics (Chap. 6). New York: Macmillan.
- Hoijer, Harry. (1956). Lexicostatistics: A critique. Language, 32, 49–60.
- Holm, Hans J. (2003). The Proportionality Trap. Or: What is wrong with lexicostatistical Subgrouping Archived 2019-06-02 at the Wayback Machine.Indogermanische Forschungen, 108, 38–46.
- Holm, Hans J. (2005). Genealogische Verwandtschaft. Kap. 45 in Quantitative Linguistik; ein internationales Handbuch. Herausgegeben von R.Köhler, G. Altmann, R. Piotrowski, Berlin: Walter de Gruyter.
- Holm, Hans J. (2007). The new Arboretum of Indo-European 'Trees'; Can new algorithms reveal the Phylogeny and even Prehistory of IE?. Journal of Quantitative Linguistics 14-2:167–214
- Hymes, Dell H. (1960). Lexicostatistics so far. Current Anthropology, 1 (1), 3–44.
- McWhorter, John. (2001). The power of Babel. New York: Freeman. ISBN 978-0-7167-4473-3.
- Nettle, Daniel. (1999). Linguistic diversity of the Americas can be reconciled with a recent colonization. in PNAS 96(6):3325–9.
- Sankoff, David (1970). "On the Rate of Replacement of Word-Meaning Relationships." Language 46.564–569.
- Sjoberg, Andree; & Sjoberg, Gideon. (1956). Problems in glottochronology. American Anthropologist, 58 (2), 296–308.
- Starostin, Sergei. Methodology Of Long-Range Comparison. 2002. pdf
- Thomason, Sarah Grey, and Kaufman, Terrence. (1988). Language Contact, Creolization, and Genetic Linguistics. Berkeley: University of California Press.
- Tischler, Johann, 1973. Glottochronologie und Lexikostatistik [Innsbrucker Beiträge zur Sprachwissenschaft 11]; Innsbruck.
- Wittmann, Henri (1969). "A lexico-statistic inquiry into the diachrony of Hittite." Indogermanische Forschungen 74.1–10.[1]
- Wittmann, Henri (1973). "The lexicostatistical classification of the French-based Creole languages." Lexicostatistics in genetic linguistics: Proceedings of the Yale conference, April 3–4, 1971, dir. Isidore Dyen, 89–99. La Haye: Mouton.[2]
- Zipf, George K. (1965). The Psychobiology of Language: an Introduction to Dynamic Philology. Cambridge, MA: M.I.T.Press.
External links
- Swadesh list in Wiktionary.
- Discussion with some statistics
- A simplified explanation of the difference between glottochronology and lexicostatistics.
- Queryable experiment: quantification of the genetic proximity between 110 languages - with trees and discussion
https://en.wikipedia.org/wiki/Glottochronology
Linguistic reconstruction is the practice of establishing the features of an unattested ancestor language of one or more given languages. There are two kinds of reconstruction:
- Internal reconstruction uses irregularities in a single language to make inferences about an earlier stage of that language – that is, it is based on evidence from that language alone.
- Comparative reconstruction, usually referred to just as reconstruction, establishes features of the ancestor of two or more related languages, belonging to the same language family, by means of the comparative method. A language reconstructed in this way is often referred to as a proto-language (the common ancestor of all the languages in a given family); examples include Proto-Indo-European and Proto-Dravidian.
Texts discussing linguistic reconstruction commonly preface reconstructed forms with an asterisk (*) to distinguish them from attested forms.
An attested word from which a root in the proto-language is reconstructed is a reflex. More generally, a reflex is the known derivative of an earlier form, which may be either attested or reconstructed. Reflexes of the same source are cognates.
Methods
First, languages that are thought to have arisen from a common proto-language must meet certain criteria in order to be grouped together; this is a process called subgrouping. Since this grouping is based purely on linguistics, manuscripts and other historical documentation should be analyzed to accomplish this step. However, the assumption that the delineations of linguistics always align with those of culture and ethnicity must not be made. One of the criteria is that the grouped languages usually exemplify shared innovation. This means that the languages must show common changes made throughout history. In addition, most grouped languages have shared retention. This is similar to the first criterion, but instead of changes, they are features that have stayed the same in both languages.[1]
Because linguistics, as in other scientific areas, seeks to reflect simplicity, an important principle in the linguistic reconstruction process is to generate the least possible number of phonemes that correspond to available data. This principle is again reflected when choosing the sound quality of phonemes, as the one which results in the fewest changes (with respect to the data) is preferred.[2]
Comparative Reconstruction makes use of two rather general principles: The Majority Principle and the Most Natural Development Principle.[3] The Majority Principle is the observation that if a cognate set displays a certain pattern (such as a repeating letter in specific positions within a word), it is likely that this pattern was retained from its mother language. The Most Natural Development Principle states that some alterations in languages, diachronically speaking, are more common than others. There are four key tendencies:
- The final vowel in a word may be omitted.
- Voiceless sounds, often between vowels, become voiced.
- Phonetic stops become fricatives.
- Consonants become voiceless at the end of words.
Sound construction
The Majority Principle is applied in identifying the most likely pronunciation of the predicted etymon (the original word from which the cognates originated). Since the Most Natural Development Principle describes the general directions in which languages appear to change, one can seek these indicators out. For example, from the word 'cantar' (Spanish) and 'chanter' (French) one can argue that, because phonetic stops generally become fricatives, the cognate with the stop [k] is older than the cognate with the fricative [ʃ], the former is most likely to more closely resemble the original pronunciation.[3]
See also
References
- Yule, George (2 January 2020). The Study of Language 2019. New York, NY: Cambridge University Printing House. ISBN 9781108499453.
Sources
- Anthony Fox, Linguistic Reconstruction: An Introduction to Theory and Method (Oxford University Press, 1995) ISBN 0-19-870001-6.
- George Yule, The Study of Language (7th Ed.) (Cambridge University Press, 2019) ISBN 978-1-108-73070-9.
- Henry M. Hoenigswald, Language Change and Linguistic Reconstruction (University of Chicago Press, 1960) ISBN 0-226-34741-9.
https://en.wikipedia.org/wiki/Linguistic_reconstruction
| Discipline | Linguistics |
|---|---|
| Language | English |
| Publication details | |
| History | 1995-present |
| Publisher | The Association for the Study of Language In Prehistory (ASLIP) (United States) |
| Frequency | Annual |
| Standard abbreviations | |
| ISO 4 | Mother Tongue |
| Links | |
Mother Tongue is an annual academic journal published by the Association for the Study of Language in Prehistory (ASLIP) that has been published since 1995.[1] Its goal is to encourage international and interdisciplinary information sharing, discussion, and debate among geneticists, paleoanthropologists, archaeologists, and historical linguists on questions relating to the origin of language and ancestral human spoken languages. This includes, but is not limited to, discussion of linguistic macrofamily hypotheses.
See also
References
External links
This article about a linguistics journal is a stub. You can help Wikipedia by expanding it. See tips for writing articles about academic journals. Further suggestions might be found on the article's talk page. |
This article about historical linguistics is a stub. You can help Wikipedia by expanding it. |
https://en.wikipedia.org/wiki/Mother_Tongue_(journal)
| Ural-Altaic | |
|---|---|
| (obsolete as a genealogical proposal) | |
| Geographic distribution | Eurasia |
| Linguistic classification | convergence zone |
| Subdivisions | |
| Glottolog | None |
.png) Distribution of Uralic, Altaic, and Yukaghir languages | |
Ural-Altaic, Uralo-Altaic or Uraltaic is a linguistic convergence zone and former language-family proposal uniting the Uralic and the Altaic (in the narrow sense) languages. It is generally now agreed that even the Altaic languages do not share a common descent: the similarities among Turkic, Mongolic and Tungusic are better explained by diffusion and borrowing.[1][2][3][4] Just as Altaic, internal structure of the Uralic family also has been debated since the family was first proposed.[5] Doubts about the validity of most or all of the proposed higher-order Uralic branchings (grouping the nine undisputed families) are becoming more common.[6][7][8] The term continues to be used for the central Eurasian typological, grammatical and lexical convergence zone.[9]
Indeed, "Ural-Altaic" may be preferable to "Altaic" in this sense. For example, J. Janhunen states that "speaking of 'Altaic' instead of 'Ural-Altaic' is a misconception, for there are no areal or typological features that are specific to 'Altaic' without Uralic."[10] Originally suggested in the 18th century, the genealogical and racial hypotheses remained debated into the mid-20th century, often with disagreements exacerbated by pan-nationalist agendas.[11]
It had many proponents in Britain.[12] Since the 1960s, the proposed language family has been widely rejected.[13][14][15][16] A relationship between the Altaic, Indo-European and Uralic families was revived in the context of the Nostratic hypothesis, which was popular for a time,[17] with for example Allan Bomhard treating Uralic, Altaic and Indo-European as coordinate branches.[18] However, Nostratic too is now rejected.[10]
History as a hypothesized language family
The concept of a Ural-Altaic ethnic and language family goes back to the linguistic theories of Gottfried Wilhelm Leibniz; in his opinion there was no better method for specifying the relationship and origin of the various peoples of the Earth, than the comparison of their languages. In his Brevis designatio meditationum de originibus gentium ductis potissimum ex indicio linguarum,[19] written in 1710, he originates every human language from one common ancestor language. Over time, this ancestor language split into two families; the Japhetic and the Aramaic. The Japhetic family split even further, into Scythian and Celtic branches. The members of the Scythian family were: the Greek language, the family of Sarmato-Slavic languages (Russian, Polish, Czech, Dalmatian, Bulgar, Slovene, Avar and Khazar), the family of Turkic languages (Turkish, Cuman, Kalmyk and Mongolian), the family of Finno-Ugric languages (Finnish, Saami, Hungarian, Estonian, Liv and Samoyed). Although his theory and grouping were far from perfect, they had a considerable effect on the development of linguistic research, especially in German-speaking countries.
In his book An historico-geographical description of the north and east parts of Europe and Asia,[20] published in 1730, Philip Johan von Strahlenberg, Swedish prisoner-of-war and explorer of Siberia, who accompanied Daniel Gottlieb Messerschmidt on his expeditions, described Finno-Ugric, Turkic, Samoyedic, Mongolic, Tungusic and Caucasian peoples as sharing linguistic and cultural commonalities. 20th century scholarship has on several occasions incorrectly credited him with proposing a Ural-Altaic language family, though he does not claim linguistic affinity between any of the six groups.[21][note 1]
Danish philologist Rasmus Christian Rask described what he called "Scythian" languages in 1834, which included Finno-Ugric, Turkic, Samoyedic, Eskimo, Caucasian, Basque and others.
The Ural-Altaic hypothesis was elaborated at least as early as 1836 by W. Schott[22] and in 1838 by F. J. Wiedemann.[23]
The "Altaic" hypothesis, as mentioned by Finnish linguist and explorer Matthias Castrén[24][25] by 1844, included the Finno-Ugric and Samoyedic, grouped as "Chudic", and Turkic, Mongolic, and Tungusic, grouped as "Tataric". Subsequently, in the latter half of the 19th century, Turkic, Mongolic, and Tungusic came to be referred to as Altaic languages, whereas Finno-Ugric and Samoyedic were called Uralic. The similarities between these two families led to their retention in a common grouping, named Ural–Altaic.
Friedrich Max Müller, the German Orientalist and philologist, published and proposed a new grouping of the non-Aryan and non-Semitic Asian languages in 1855. In his work The Languages of the Seat of War in the East, he called these languages "Turanian". Müller divided this group into two subgroups, the Southern Division, and the Northern Division.[26] In the long run, his evolutionist theory about languages' structural development, tying growing grammatical refinement to socio-economic development, and grouping languages into 'antediluvian', 'familial', 'nomadic', and 'political' developmental stages,[27] proved unsound, but his Northern Division was renamed and re-classed as the "Ural-Altaic languages".
Between the 1850s and 1870s, there were efforts by Frederick Roehrig to including some Native American languages in a "Turanian" or "Ural-Altaic" family, and between the 1870s and 1890s, there was speculation about links with Basque.[28]
In Hungary, where the national language is Uralic but with heavy historical Turkic influence -- a fact which by itself spurred the popularity of the "Ural-Altaic" hypothesis -- the idea of the Ural–Altaic relationship remained widely implicitly accepted in the late 19th and the mid-20th century, though more out of pan-nationalist than linguistic reasons, and without much detailed research carried out.[clarification needed] Elsewhere the notion had sooner fallen into discredit, with Ural–Altaic supporters elsewhere such as the Finnish Altaicist Martti Räsänen being in the minority.[29] The contradiction between Hungarian linguists' convictions and the lack of clear evidence eventually provided motivation for scholars such as Aurélien Sauvageot and Denis Sinor to carry out more detailed investigation of the hypothesis, which so far has failed to yield generally accepted results. Nicholas Poppe in his article The Uralo-Altaic Theory in the Light of the Soviet Linguistics (1940) also attempted to refute Castrén's views by showing that the common agglutinating features may have arisen independently.[30]
Beginning in the 1960s, the hypothesis came to be seen even more controversial, due to the Altaic family itself also falling out universal acceptance. Today, the hypothesis that Uralic and Altaic are related more closely to one another than to any other family has almost no adherents.[31] In his Altaic Etymological Dictionary, co-authored with Anna V. Dybo and Oleg A. Mudrak, Sergei Starostin characterized the Ural–Altaic hypothesis as "an idea now completely discarded".[31] There are, however, a number of hypotheses that propose a larger macrofamily including Uralic, Altaic and other families. None of these hypotheses has widespread support. In Starostin's sketch of a "Borean" super-phylum, he puts Uralic and Altaic as daughters of an ancestral language of c. 9,000 years ago from which the Dravidian languages and the Paleo-Siberian languages, including Eskimo–Aleut, are also descended. He posits that this ancestral language, together with Indo-European and Kartvelian, descends from a "Eurasiatic" protolanguage some 12,000 years ago, which in turn would be descended from a "Borean" protolanguage via Nostratic.[32]
In the 1980s, Russian linguist N. D. Andreev (Nikolai Dmitrievich Andreev) proposed a "Boreal languages" hypothesis linking the Indo-European, Uralic, and Altaic (including Korean in his later papers) language families. Andreev also proposed 203 lexical roots for his hypothesized Boreal macrofamily. After Andreev's death in 1997, the Boreal hypothesis was further expanded by Sorin Paliga (2003, 2007).[33][34]
Angela Marcantonio (2002) argues that there is no sufficient evidence for a Finno-Ugric or Uralic group connecting the Finno-Permic and Ugric languages, and suggests that they are no more closely related to each other than either is to Turkic, thereby positing a grouping very similar to Ural–Altaic or indeed to Castrén's original Altaic proposal. This thesis has been criticized by mainstream Uralic scholars.[35][36][37]
Typology
There is general agreement on several typological similarities being widely found among the languages considered under Ural–Altaic:[38]
- head-final and subject–object–verb word order
- in most of the languages, vowel harmony
- morphology that is predominantly agglutinative and suffixing
- zero copula
- non-finite clauses
- lack of grammatical gender
- lack of consonant clusters in word-initial position
- having a separate verb for existential clause which is different from ordinary possession verbs like "to have"
Such similarities do not constitute sufficient evidence of genetic relationship all on their own, as other explanations are possible. Juha Janhunen has argued that although Ural–Altaic is to be rejected as a genealogical relationship, it remains a viable concept as a well-defined language area, which in his view has formed through the historical interaction and convergence of four core language families (Uralic, Turkic, Mongolic and Tungusic), and their influence on the more marginal Korean and Japonic.[39]
Contrasting views on the typological situation have been presented by other researchers. Michael Fortescue has connected Uralic instead as a part of an Uralo-Siberian typological area (comprising Uralic, Yukaghir, Chukotko-Kamchatkan and Eskimo–Aleut), contrasting with a more narrowly defined Altaic typological area;[40] while Anderson has outlined a specifically Siberian language area, including within Uralic only the Ob-Ugric and Samoyedic groups; within Altaic most of the Tungusic family as well as Siberian Turkic and Buryat (Mongolic); as well as Yukaghir, Chukotko-Kamchatkan, Eskimo–Aleut, Nivkh, and Yeniseian.[41]
Relationship between Uralic and Altaic
The Altaic language family was generally accepted by linguists from the late 19th century up to the 1960s, but since then has been in dispute. For simplicity's sake, the following discussion assumes the validity of the Altaic language family.
Two senses should be distinguished in which Uralic and Altaic might be related.
- Do Uralic and Altaic have a demonstrable genetic relationship?
- If they do have a demonstrable genetic relationship, do they form a valid linguistic taxon? For example, Germanic and Iranian have a genetic relationship via Proto-Indo-European, but they do not form a valid taxon within the Indo-European language family, whereas in contrast Iranian and Indo-Aryan do via Indo-Iranian, a daughter language of Proto-Indo-European that subsequently calved into Indo-Aryan and Iranian.
In other words, showing a genetic relationship does not suffice to establish a language family, such as the proposed Ural–Altaic family; it is also necessary to consider whether other languages from outside the proposed family might not be at least as closely related to the languages in that family as the latter are to each other. This distinction is often overlooked but is fundamental to the genetic classification of languages.[42] Some linguists indeed maintain that Uralic and Altaic are related through a larger family, such as Eurasiatic or Nostratic, within which Uralic and Altaic are no more closely related to each other than either is to any other member of the proposed family, for instance than Uralic or Altaic is to Indo-European (for example Greenberg).[43]
To demonstrate the existence of a language family, it is necessary to find cognate words that trace back to a common proto-language. Shared vocabulary alone does not show a relationship, as it may be loaned from one language to another or through the language of a third party.
There are shared words between, for example, Turkic and Ugric languages, or Tungusic and Samoyedic languages, which are explainable by borrowing. However, it has been difficult to find Ural–Altaic words shared across all involved language families. Such words should be found in all branches of the Uralic and Altaic trees and should follow regular sound changes from the proto-language to known modern languages, and regular sound changes from Proto-Ural–Altaic to give Proto-Uralic and Proto-Altaic words should be found to demonstrate the existence of a Ural–Altaic vocabulary. Instead, candidates for Ural–Altaic cognate sets can typically be supported by only one of the Altaic subfamilies.[44] In contrast, about 200 Proto-Uralic word roots are known and universally accepted, and for the proto-languages of the Altaic subfamilies and the larger main groups of Uralic, on the order of 1000–2000 words can be recovered.
Some[who?] linguists point out strong similarities in the personal pronouns of Uralic and Altaic languages, although the similarities also exist with the Indo-European pronouns as well.
The basic numerals, unlike those among the Indo-European languages (compare Proto-Indo-European numerals), are particularly divergent between all three core Altaic families and Uralic, and to a lesser extent even within Uralic.[45]
| Numeral | Uralic | Turkic | Mongolic | Tungusic | ||
|---|---|---|---|---|---|---|
| Finnish | Hungarian | Tundra Nenets | Old Turkic | Classical Mongolian | Proto-Tungusic | |
| 1 | yksi | egy | ŋob | bir | nigen | *emün |
| 2 | kaksi | kettő/két | śiďa | eki | qoyar | *džör |
| 3 | kolme | három | ńax°r | üs | ɣurban | *ilam |
| 4 | neljä | négy | ťet° | tört | dörben | *dügün |
| 5 | viisi | öt | səmp°ľaŋk° | baš | tabun | *tuńga |
| 6 | kuusi | hat | mət°ʔ | eltı | ǰirɣuɣan | *ńöŋün |
| 7 | seitsemän | hét | śīʔw° | jeti | doluɣan | *nadan |
| 8 | kahdeksan | nyolc | śid°nťet° | säkiz | naiman | *džapkun |
| 9 | yhdeksän | kilenc | xasuyu" | toquz | yisün | *xüyägün |
| 10 | kymmenen | tíz | yūʔ | on | arban | *džuvan |
One alleged Ural-Altaic similarity among this data are the Hungarian (három) and Mongolian (ɣurban) numerals for '3'. According to Róna-Tas (1983),[46] elevating this similarity to a hypothesis of common origin would still require several ancillary hypotheses:
- that this Finno-Ugric lexeme, and not the incompatible Samoyedic lexeme, is the original Uralic numeral;
- that this Mongolic lexeme, and not the incompatible Turkic and Tungusic lexemes, is the original Altaic numeral;
- that the Hungarian form with -r-, and not the -l- seen in cognates such as in Finnish kolme, is more original;
- that -m in the Hungarian form is originally a suffix, since -bVn, found also in other Mongolian numerals, is also a suffix and not an original part of the word root;
- that the voiced spirant ɣ- in Mongolian can correspond to the voiceless stop *k- in Finno-Ugric (known to be the source of Hungarian h-).
Sound correspondences
The following consonant correspondences between Uralic and Altaic are asserted by Poppe (1983):[47]
- Word-initial bilabial stop: Uralic *p- = Altaic *p- (> Turkic and Mongolic *h-)
- Sibilants: Uralic *s, *š, *ś = Altaic *s
- Nasals: Uralic *n, *ń, *ŋ = Altaic *n, *ń, *ŋ (in Turkic word-initial *n-, *ń- > *j-; in Mongolic *ń(V) > *n(i))
- Liquids: Uralic *-l-, *-r- = Altaic *-l-, *r-[note 2]
As a convergence zone
Regardless of a possible common origin or lack thereof, Uralic-Altaic languages can be spoken of as a convergence zone. Although it has not yet been possible to demonstrate a genetic relationship or a significant amount of common vocabulary between the languages other than loanwords, according to the linguist Juha Jahunen, the languages must have had a common linguistic homeland. The Turkic, Mongolic and Tungusic languages have been spoken in the Manchurian region, and there is little chance that a similar structural typology of Uralic languages could have emerged without close contact with them.[48][49][50] The languages of Turkish and Finnish have many similar structures, such as vowel harmony and agglutination.[51]
Similarly, according to Janhunen, the common typology of the Altaic languages can be inferred as a result of mutual contacts in the past, perhaps from a few thousand years ago.[52]
See also
Notes
- Treated only word-medially.
References
- Janhunen 2009: 62.
Bibliography
- Greenberg, Joseph H. (2000). Indo-European and Its Closest Relatives: The Eurasiatic Language Family, Volume 1: Grammar. Stanford: Stanford University Press.
- Greenberg, Joseph H. (2005). Genetic Linguistics: Essays on Theory and Method, edited by William Croft. Oxford: Oxford University Press.
- Marcantonio, Angela (2002). The Uralic Language Family: Facts, Myths and Statistics. Publications of the Philological Society. Vol. 35. Oxford – Boston: Blackwell.
- Ponaryadov, V. V. (2011). A tentative reconstruction of Proto-Uralo-Mongolian. Syktyvkar. 44 p. (Scientific Reports / Komi Science Center of the Ural Division of the Russian Academy of Sciences; Issue 510).
- Shirokogoroff, S. M. (1931). Ethnological and Linguistical Aspects of the Ural–Altaic Hypothesis. Peiping, China: The Commercial Press.
- Sinor, Denis (1988). "The Problem of the Ural-Altaic relationship". In Sinor, Denis (ed.). The Uralic Languages: Description, History and Modern Influences. Leiden: Brill. pp. 706–741.
- Starostin, Sergei A., Anna V. Dybo, and Oleg A. Mudrak. (2003). Etymological Dictionary of the Altaic Languages. Brill Academic Publishers. ISBN 90-04-13153-1.
- Vago, R. M. (1972). Abstract Vowel Harmony Systems in Uralic and Altaic Languages. Bloomington: Indiana University Linguistics Club.
External links
- Review of Marcantonio (2002) by Johanna Laasko
- Keane, Augustus Henry (1911). . Encyclopædia Britannica. Vol. 27 (11th ed.). pp. 784–786. This reflects the contemporary transitional state of understanding of the relationships among the languages.
- Whitney, William Dwight; Rhyn, G. A. F. Van (1879). . The American Cyclopædia.
https://en.wikipedia.org/wiki/Ural-Altaic_languages
| Austric | |
|---|---|
| (proposed) | |
| Geographic distribution | Southeast Asia, Pacific Islands, South Asia, East Asia, Madagascar |
| Linguistic classification | Proposed language family |
| Subdivisions |
|
| Glottolog | None |
 | |
The Austric languages are a proposed language family that includes the Austronesian languages spoken in Taiwan, Maritime Southeast Asia, the Pacific Islands, and Madagascar, as well as the Austroasiatic languages spoken in Mainland Southeast Asia and South Asia. A genetic relationship between these language families is seen as plausible by some scholars, but remains unproven.[1][2]
Additionally, the Kra–Dai languages and Hmong–Mien languages are included by some linguists, and even Japanese was speculated to be Austric in an early version of the hypothesis by Paul K. Benedict.[3]
History
The Austric macrofamily was first proposed by the German missionary Wilhelm Schmidt in 1906. He showed phonological, morphological, and lexical evidence to support the existence of an Austric phylum consisting of Austroasiatic and Austronesian.[4][a] Schmidt's proposal had a mixed reception among scholars of Southeast Asian languages, and received only little scholarly attention in the following decades.[5]
Research interest into Austric resurged in the late 20th century,[6] culminating in a series of articles by La Vaughn H. Hayes who presented a corpus of Proto-Austric vocabulary together with a reconstruction of Proto-Austric phonology,[7] and by Lawrence Reid, focussing on morphological evidence.[8]
Evidence
Reid (2005) lists the following pairs as "probable" cognates between Proto-Austroasiatic and Proto-Austronesian.[9]
| Gloss | ashes | dog | snake | belly | eye | father | mother | rotten | buy |
|---|---|---|---|---|---|---|---|---|---|
| Proto-Austroasiatic | *qabuh | *cu(q) | *[su](l̩)aR | *taʔal/*tiʔal | *mə(n)ta(q) | *(qa)ma(ma) | *(na)na | *ɣok | *pə[l̩]i |
| Proto-Austronesian | *qabu | *asu | *SulaR | *tiaN | *maCa | *t-ama | *t-ina | *ma-buRuk | *beli |
Among the morphological evidence, he compares reconstructed affixes such as the following, and notes that shared infixes are less likely to be borrowed (for a further discussion of infixes in Southeast Asian languages, see also Barlow 2022[10]).[11]
- prefix *pa- 'causative' (Proto-Austroasiatic, Proto-Austronesian)
- infix *-um- 'agentive' (Proto-Austroasiatic, Proto-Austronesian)
- infix *-in- 'instrumental' (Proto-Austroasiatic), 'nominalizer' (Proto-Austronesian)
Below are 10 selected Austric lexical comparisons by Diffloth (1994), as cited in Sidwell & Reid (2021):[12][13]
| Gloss | Proto-Austroasiatic | Proto-Austronesian |
|---|---|---|
| ‘fish’ | *ʔaka̰ːʔ | *Sikan |
| ‘dog’ | *ʔac(ṵə)ʔ | *asu |
| ‘wood’ | *kəɟh(uː)ʔ | *kaSi |
| ‘eye’ | *ma̰t | *maCa |
| ‘bone’ | *ɟlʔaːŋ | *CuqelaN |
| ‘hair’ | *s(ɔ)k | *bukeS |
| ‘bamboo rat’ | Khmu dəkən | Malay dəkan |
| ‘molar’ | Khmer thkìəm | Malay gərham |
| ‘left’ | p-Monic *ɟwiːʔ | *ka-wiʀi |
| ‘ashes’ | Stieng *buh | *qabu |
Extended proposals
The first extension to Austric was first proposed Wilhelm Schmidt himself, who speculated about including Japanese within Austric, mainly because of assumed similarities between Japanese and the Austronesian languages.[14] While the proposal about a link between Austronesian and Japanese still enjoys some following as a separate hypothesis, the inclusion of Japanese was not adopted by later proponents of Austric.
In 1942, Paul K. Benedict provisionally accepted the Austric hypothesis and extended it to include the Kra–Dai (Thai–Kadai) languages as an immediate sister branch to Austronesian, and further speculated on the possibility to include the Hmong–Mien (Miao–Yao) languages as well.[15] However, he later abandoned the Austric proposal in favor of an extended version of the Austro-Tai hypothesis.[16]
Sergei Starostin adopted Benedict's extended 1942 version of Austric (i.e. including Kra–Dai and Hmong–Mien) within the framework of his larger Dené–Daic proposal, with Austric as a coordinate branch to Dené–Caucasian, as shown in the tree below.[17]
| Dene-Daic |
| ||||||||||||||||||||||||||||||
|
|
Another long-range proposal for wider connections of Austric was brought forward by John Bengtson, who grouped Nihali and Ainu together with Austroasiatic, Austronesian, Hmong–Mien, and Kra–Dai in a "Greater Austric" family.[18]
Reception
In the second half of the last century, Paul K. Benedict raised a vocal critique of the Austric proposal, eventually calling it an 'extinct' proto-language.[19][16]
Hayes' lexical comparisons, which were presented as supporting evidence for Austric between 1992 and 2001, were criticized for the greater part as methodologically unsound by several reviewers.[20][21] Robert Blust, a leading scholar in the field of Austronesian comparative linguistics, pointed out "the radical disjunction of morphological and lexical evidence" which characterizes the Austric proposal; while he accepts the morphological correspondences between Austronesian and Austroasiatic as possible evidence for a remote genetic relationship, he considers the lexical evidence unconvincing.[22]
A 2015 analysis using the Automated Similarity Judgment Program (ASJP) did not support the Austric hypothesis. In this analysis, the supposed "core" components of Austric were assigned to two separate, unrelated clades: Austro-Tai and Austroasiatic-Japonic.[23] Note however that ASJP is not widely accepted among historical linguists as an adequate method to establish or evaluate relationships between language families.[24]
Distributions

Distribution of Austroasiatic languages

Distribution of Austronesian languages
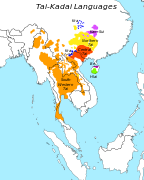
Distribution of Kra–Dai languages

Distribution of Hmong–Mien languages




See also
- East Asian languages
- Austro-Tai languages
- Sino-Austronesian languages
- Mainland Southeast Asia linguistic area
- Classification of Southeast Asian languages
Notes
- The terms "Austroasiatic" and "Austronesian" were in fact both coined by Schmidt. The previous common designations "Mon-Khmer" and "Malayo-Polynesian" are still in use, but each with a scope that is more limited than "Austroasiatic" and "Austronesian".
References
- Cf. comments by Adelaar, Blust and Campbell in Holman (2011).
Works cited
- Benedict, Paul K. (1942). "Thai, Kadai, and Indonesian: A New Alignment in Southeastern Asia". American Anthropologist. 4 (44): 576–601. doi:10.1525/aa.1942.44.4.02a00040.
- ——— (1976). "Austro-Thai and Austroasiatic". In Jenner, Philip N.; Thompson, Laurence C.; Starosta, Stanley (eds.). Austroasiatic Studies, Part I. Oceanic Linguistics Special Publications. Honolulu: University of Hawaiʻi Press. pp. 1–36. JSTOR 20019153.
- ——— (1991). "Austric: An 'Extinct' Proto-language". In Davidson, Jeremy H. C. S. (ed.). Austroasiatic Languages: Essays in Honour of H. L. Shorto. London: School of Oriental and African Studies. pp. 7–11.
- Blust, Robert (2013). The Austronesian Languages (revised ed.). Australian National University. hdl:1885/10191. ISBN 978-1-922185-07-5.
- Diffloth, Gerard (1990). "What Happened to Austric?" (PDF). Mon–Khmer Studies. 16–17: 1–9.
- ——— (1994). "The lexical evidence for Austric so far". Oceanic Linguistics. 33 (2): 309–321. doi:10.2307/3623131. JSTOR 3623131.
- van Driem, George (2001). Languages of the Himalayas. Vol. 1. Leiden: BRILL. ISBN 9004120629.
- ——— (2005). "Sino-Austronesian vs. Sino-Caucasian, Sino-Bodic vs. Sino-Tibetan, and Tibeto-Burman as default theory" (PDF). In Yadava, Yogendra P. (ed.). Contemporary Issues in Nepalese Linguistics. Linguistic Society of Nepal. pp. 285–338. ISBN 978-99946-57-69-8.
- Hayes, La Vaughn H. (1992). "On the Track of Austric, Part I: Introduction" (PDF). Mon–Khmer Studies. 21: 143–77.
- ——— (1997). "On the Track of Austric, Part II: Consonant Mutation in Early Austroasiatic" (PDF). Mon–Khmer Studies. 27: 13–41.
- ——— (1999). "On the Track of Austric, Part III: Basic Vocabulary Correspondence" (PDF). Mon–Khmer Studies. 29: 1–34.
- ——— (2000). "The Austric Denti-alveolar Sibilants". Mother Tongue. 5: 1–12.
- ——— (2001). "On the Origin of Affricates in Austric". Mother Tongue. 6: 95–117.
- Holman, Eric W. (2011). "Automated Dating of the World's Language Families Based on Lexical Similarity" (PDF). Current Anthropology. 52 (6): 841–875. doi:10.1086/662127. hdl:2066/94255. S2CID 60838510.
- Jäger, Gerhard (2015). "Support for linguistic macrofamilies from weighted sequence alignment". PNAS. 112 (41): 12752–12757. Bibcode:2015PNAS..11212752J. doi:10.1073/pnas.1500331112. PMC 4611657. PMID 26403857.
- Reid, Lawrence A. (1994). "Morphological evidence for Austric" (PDF). Oceanic Linguistics. 33 (2): 323–344. doi:10.2307/3623132. hdl:10125/32987. JSTOR 3623132.
- ——— (1999). "New linguistic evidence for the Austric hypothesis". In Zeitoun, Elizabeth; Li, Paul Jen-kuei (eds.). Selected Papers from the Eighth International Conference on Austronesian Linguistics. Taipei: Academia Sinica. pp. 5–30.
- ——— (2005). "The current status of Austric: A review and evaluation of the lexical and morphosyntactic evidence". In Sagart, Laurent; Blench, Roger; Sanchez-Mazas, Alicia (eds.). The peopling of East Asia: putting together archaeology, linguistics and genetics. London: Routledge Curzon. hdl:10125/33009.
- ——— (2009). "Austric Hypothesis". In Brown, Keith; Ogilvie, Sarah (eds.). Concise Encyclopaedia of Languages of the World. Oxford: Elsevier. pp. 92–94.
- Schmidt, Wilhelm (1906). "Die Mon–Khmer-Völker, ein Bindeglied zwischen Völkern Zentralasiens und Austronesiens ('[The Mon–Khmer Peoples, a Link between the Peoples of Central Asia and Austronesia')". Archiv für Anthropologie. 5: 59–109.
- ——— (1930). "Die Beziehungen der austrischen Sprachen zum Japanischen ('The connections of the Austric languages to Japanese')". Wiener Beitrag zur Kulturgeschichte und Linguistik. 1: 239–51..
- Shorto, H. L. (1976). "In Defense of Austric". Computational Analyses of Asian and African Languages. 6: 95–104.
- Solnit, David B. (1992). "Japanese/Austro-Tai By Paul K. Benedict (review)". Language. 68 (1): 188–196. doi:10.1353/lan.1992.0061. ISSN 1535-0665. S2CID 141811621.
Further reading
- Blazhek, Vaclav. 2000. Comments on Hayes "The Austric Denti-alveolar Sibilants". Mother Tongue V:15-17.
- Blust, Robert. 1996. Beyond the Austronesian homeland: The Austric hypothesis and its implications for archaeology. In: Prehistoric Settlement of the Pacific, ed. by Ward H.Goodenough, ISBN 978-0-87169-865-0 DIANE Publishing Co, Collingdale PA, 1996, pp. 117–137. (Transactions of the American Philosophical Society 86.5. (Philadelphia: American Philosophical Society).
- Blust, Robert. 2000. Comments on Hayes, "The Austric Denti-alveolar Sibilants". Mother Tongue V:19-21.
- Fleming, Hal. 2000. LaVaughn Hayes and Robert Blust Discuss Austric. Mother Tongue V:29-32.
- Hayes, La Vaughn H. 2000. Response to Blazhek's Comments. Mother Tongue V:33-4.
- Hayes, La Vaughn H. 2000. Response to Blust's Comments. Mother Tongue V:35-7.
- Hayes, La Vaughn H. 2000. Response to Fleming's Comments. Mother Tongue V:39-40.
- Hayes, La Vaughn H. 2001. Response to Sidwell. Mother Tongue VI:123-7.
- Larish, Michael D. 2006. Possible Proto-Asian Archaic Residue and the Statigraphy of Diffusional Cumulation in Austro-Asian Languages. Paper presented at the Tenth International Conference on Austronesian Linguistics, 17–20 January 2006, Puerto Princesa City, Palawan, Philippines.
- Reid, Lawrence A. 1996. The current state of linguistic research on the relatedness of the language families of East and Southeast Asia. In: Ian C. Glover and Peter Bellwood, editorial co-ordinators, Indo-Pacific Prehistory: The Chiang Mai Papers, Volume 2, pp . 87-91. Bulletin of the Indo-Pacific Prehistory Association 15. Canberra: Australian National University.
- Sidwell, Paul. 2001. Comments on La Vaughn H. Hayes' "On the Origin of Affricates in Austric". Mother Tongue VI:119-121.
- Van Driem, George. 2000. Four Austric Theories. Mother Tongue V:23-27.
External links
- Glossary of purported lexical links among Austronesian and Austroasiatic languages
- Austronesian Basic Vocabulary Database: Austronesian, Tai–Kadai, Hmong–Mien, Austro-Asiatic word lists
| Authority control: National |
|---|
https://en.wikipedia.org/wiki/Austric_languages
| Nostratic | |
|---|---|
| (controversial) | |
| Geographic distribution | Europe, Asia except for the southeast, North and Northeast Africa, the Arctic |
| Linguistic classification | Hypothetical macrofamily |
| Subdivisions |
|
| Glottolog | None |

Nostratic is a hypothetical macrofamily, which includes many of the indigenous language families of Eurasia, although its exact composition and structure vary among proponents. It typically comprises Kartvelian, Indo-European and Uralic languages; some languages from the similarly controversial Altaic family; the Afroasiatic languages; as well as the Dravidian languages (sometimes also Elamo-Dravidian).
The hypothetical ancestral language of the Nostratic family is called Proto-Nostratic.[1] According to Allan R. Bomhard, Proto-Nostratic would have been spoken between 15,000 and 12,000 BCE, in the Epipaleolithic period, close to the end of the last glacial period, perhaps in or near the Fertile Crescent.[2][3]
The Nostratic hypothesis originates with Holger Pedersen in the early 20th century. The name "Nostratic" is due to Pedersen (1903), derived from the Latin nostrates "fellow countrymen". The hypothesis was significantly expanded in the 1960s by Soviet linguists, notably Vladislav Illich-Svitych and Aharon Dolgopolsky, termed the "Moscovite school" by Allan Bomhard (2008, 2011, and 2014), and it has received renewed attention in English-speaking academia since the 1990s.
The hypothesis is controversial and has varying degrees of acceptance amongst linguists worldwide with most rejecting Nostratic and many other macrofamily hypotheses.[4] In Russia, it is endorsed by a minority of linguists, such as Vladimir Dybo, but is not a generally accepted hypothesis.[citation needed] Some linguists take an agnostic view.[5][6][7][8] Eurasiatic, a similar grouping, was proposed by Joseph Greenberg (2000) and endorsed by Merritt Ruhlen: it is taken as a subfamily of Nostratic by Bomhard (2008).
History of research
Origin of the Nostratic hypothesis
The last quarter of the 19th century saw various linguists putting forward proposals linking the Indo-European languages to other language families, such as Finno-Ugric and Altaic.[9]
These proposals were taken much further in 1903 when Holger Pedersen proposed "Nostratic", a common ancestor for the Indo-European, Finno-Ugric, Samoyed, Turkish, Mongolian, Manchu, Yukaghir, Eskimo, Semitic, and Hamitic languages, with the door left open to the eventual inclusion of others.
The name Nostratic derives from the Latin word nostrās, meaning 'our fellow-countryman' (plural: nostrates) and has been defined, since Pedersen, as consisting of those language families that are related to Indo-European.[10] Merritt Ruhlen notes that this definition is not properly taxonomic but amorphous, since there are broader and narrower degrees of relatedness, and moreover, some linguists who broadly accept the concept (such as Greenberg and Ruhlen himself) have criticised the name as reflecting the ethnocentrism frequent among Europeans at the time.[11] Martin Bernal has described the term as distasteful because it implies that speakers of other language families are excluded from academic discussion.[12] Even so, the concept arguably transcends ethnocentric associations. (Indeed, Pedersen's older contemporary Henry Sweet attributed some of the resistance by Indo-European specialists to hypotheses of wider genetic relationships as "prejudice against dethroning [Indo-European] from its proud isolation and affiliating it to the languages of yellow races".)[13] Proposed alternative names such as Mitian, formed from the characteristic Nostratic first- and second-person pronouns mi 'I' and ti 'you' (exactly 'thee'),[14] have not attained the same currency.
An early supporter was the French linguist Albert Cuny—better known for his role in the development of the laryngeal theory[15]—who published his Recherches sur le vocalisme, le consonantisme et la formation des racines en « nostratique », ancêtre de l'indo-européen et du chamito-sémitique ('Researches on the Vocalism, Consonantism, and Formation of Roots in "Nostratic", Ancestor of Indo-European and Hamito-Semitic') in 1943. Although Cuny enjoyed a high reputation as a linguist, the work was coldly received.
Moscow School of Comparative Linguistics
While Pedersen's Nostratic hypothesis did not make much headway in the West, it became quite popular in what was then the Soviet Union. Working independently at first, Vladislav Illich-Svitych and Aharon Dolgopolsky elaborated the first version of the contemporary form of the hypothesis during the 1960s. They expanded it to include additional language families. Illich-Svitych also prepared the first dictionary of the hypothetical language.[16]
A principal source for the items in Illich-Svitych's dictionary was the earlier work of Alfredo Trombetti (1866–1929), an Italian linguist who had developed a classification scheme for all the world's languages, widely reviled at the time[17] and subsequently ignored by almost all linguists. In Trombetti's time, a widely held view on classifying languages was that similarity in inflections is the surest proof of genetic relationship. In the interim, the view had taken hold that the comparative method—previously used as a means of studying languages already known to be related and without any thought of classification[18]—is the most effective means to establish genetic relationship, eventually hardening into the conviction that it is the only legitimate means to do so. This view was basic to the outlook of the new Nostraticists. Although Illich-Svitych adopted many of Trombetti's etymologies, he sought to validate them by a systematic comparison of the sound systems of the languages concerned.
21st century
The chief events in Nostratic studies in 2008 were the online publication of the latest version of Dolgopolsky's Nostratic Dictionary[19] and the publication of Allan Bomhard's comprehensive treatment of the subject, Reconstructing Proto-Nostratic, in 2 volumes.[20] 2008 also saw the opening of a website, Nostratica, devoted to providing important texts in Nostratic studies online, which is now offline.[21] Also significant was Bomhard's partly critical review of Dolgopolsky's dictionary, in which he argued that only those Nostratic etymologies that are strongest should be included, in contrast to Dolgopolsky's more expansive approach, which includes many etymologies that are possible but not secure.[22]
In early 2014, Allan Bomhard published his latest monograph on Nostratic, A Comprehensive Introduction to Nostratic Comparative Linguistics.[23]
Constituent language families
The language families proposed for inclusion in Nostratic vary, but all Nostraticists agree on a common core of language families, with differences of opinion appearing over the inclusion of additional families.
The three groups universally accepted among Nostraticists are Indo-European, Uralic, and Altaic; the validity of the Altaic family, while itself controversial, is taken for granted by Nostraticists. Nearly all also include the Kartvelian and Dravidian language families.[24]
Following Pedersen, Illich-Svitych, and Dolgopolsky, most advocates of the theory have included Afroasiatic, though criticisms by Joseph Greenberg and others from the late 1980s onward suggested a reassessment of this position.
The Sumerian and Etruscan languages, usually regarded as language isolates, are thought by some to be Nostratic languages as well. Others, however, consider one or both to be members of another macrofamily called Dené–Caucasian. Another notional isolate, the Elamite language, also figures in a number of Nostratic classifications. It is frequently grouped with Dravidian as Elamo-Dravidian.[25][26]
In 1987 Joseph Greenberg proposed a similar macrofamily which he called Eurasiatic.[27] It included the same "Euraltaic" core (Indo-European, Uralic, and Altaic), but excluded some of the above-listed families, most notably Afroasiatic. At about this time Russian Nostraticists, notably Sergei Starostin, constructed a revised version of Nostratic which was slightly broader than Greenberg's grouping but which similarly left out Afroasiatic.
Beginning in the early 2000s, a consensus emerged among proponents of the Nostratic hypothesis. Greenberg basically agreed with the Nostratic concept, though he stressed a deep internal division between its northern 'tier' (his Eurasiatic) and a southern 'tier' (principally Afroasiatic and Dravidian). The American Nostraticist Allan Bomhard considers Eurasiatic a branch of Nostratic alongside other branches: Kartvelian, Afroasiatic, and Elamo-Dravidian. Similarly, Georgiy Starostin (2002) arrives at a tripartite overall grouping: he considers Afroasiatic, Nostratic and Elamite to be roughly equidistant and more closely related to each other than to anything else.[28] Sergei Starostin's school has now re-included Afroasiatic in a broadly defined Nostratic, while reserving the term Eurasiatic to designate the narrower subgrouping which comprises the rest of the macrofamily. Recent proposals thus differ mainly on the precise placement of Kartvelian and Dravidian.
According to Greenberg, Eurasiatic and Amerind form a genetic node, being more closely related to each other than either is to "the other families of the Old World".[29] There are a number of hypotheses incorporating Nostratic into an even broader linguistic 'mega-phylum', sometimes called Borean, which would also include at least the Dené–Caucasian and perhaps the Amerind and Austric superfamilies. The term SCAN has been used for a group that would include Sino-Caucasian, Amerind, and Nostratic.[30]
The following table summarizes the constituent language families of Nostratic, as described by Holger Pedersen, Vladislav Illich-Svitych, Sergei Starostin, Allan Bomhard, and Aharon Dolgopolsky.
| Linguist | Indo-European | Afroasiatic | Uralic | Altaic | Dravidian | Kartvelian | Eskimo-Aleut | Yukaghir | Sumerian | Chukchi-Kamchatkan | Gilyak | Etruscan |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pedersen[31] | ||||||||||||
| Illich-Svitych[32] | ||||||||||||
| Starostin[33] | ||||||||||||
| Bomhard[34] | ||||||||||||
| Dolgopolsky[35] | ||||||||||||
|
Urheimat and differentiation
Allan Bomhard and Colin Renfrew are in broad agreement with the earlier conclusions of Illich-Svitych and Dolgopolsky in seeking the Nostratic Urheimat (original homeland) within the Mesolithic (or Epipaleolithic) in the Fertile Crescent, the stage which directly preceded the Neolithic and was transitional to it.
Looking at the cultural assemblages of this period, two sequences, in particular, stand out as possible archeological correlates of the earliest Nostratians or their immediate precursors. Both hypotheses place Proto-Nostratic within the Fertile Crescent at around the end of the last glacial period.
- The first of these is focused on the Levant. The Kebaran culture (20,000–17,000 BP)[36] not only introduced the microlithic assemblage into the region, it also has African affinity specifically with the Ouchtata retouch technique associated with the microlithic Halfan culture of Egypt (20,000–17,000 BP)[37] The Kebarans in their turn were directly ancestral to the succeeding Natufian culture (10,500–8500 BCE), which has enormous significance for prehistorians as the clearest evidence of hunters and gatherers in actual transition to Neolithic food production. Both cultures extended their influence outside the region into southern Anatolia. For example, in Cilicia the Belbaşı culture (13,000–10,000 BC) shows Kebaran influence, while the Beldibi culture (10,000–8500 BC) shows clear Natufian influence.
- The second possibility as a culture associated with the Nostratic family is the Zarzian (12,400–8500 BC) culture of the Zagros mountains, stretching northwards into Kohistan in the Caucasus and eastwards into Iran. In western Iran, the M'lefatian culture (10,500–9000 BC) was ancestral to the assemblages of Ali Tappah (9000–5000 BC) and Jeitun (6000–4000 BC). Still further east, the Hissar culture has been seen as the Mesolithic precursor to the Keltiminar culture (5500–3500 BC) of the Kyrgyz steppe.
It has been proposed that the broad spectrum revolution[38] of Kent Flannery (1969),[39] associated with microliths, the use of the bow and arrow, and the domestication of the dog, all of which are associated with these cultures, might have been the cultural "motor" that led to their expansion. Certainly, cultures which appeared at Franchthi Cave in the Aegean and Lepenski Vir in the Balkans, and the Murzak-Koba (9100–8000 BC) and Grebenki (8500–7000 BC) cultures of the Ukrainian steppe, all displayed these adaptations.
Bomhard (2008) suggests a differentiation of Proto-Nostratic by 8,000 BCE, the beginning of the Neolithic Revolution in the Levant, over a territory spanning the entire Fertile Crescent and beyond into the Caucasus (Proto-Kartvelian), Egypt and along the Red Sea to the Horn of Africa (Proto-Afroasiatic), the Iranian Plateau (Proto-Elamo-Dravidian) and into Central Asia (Proto-Eurasiatic, to be further subdivided by 5,000 BCE into Proto-Indo-European, Proto-Uralic and Proto-Altaic).
According to some scholarly opinion the Kebaran is derived from the Levantine Upper Palaeolithic in which the microlithic component originated,[40] although microlithic cultures were earlier found in Africa.
Ouchtata retouch is also a characteristic of the Late Ahmarian Upper Palaeolithic culture of the Levant and may not indicate African influence.[40]
Reconstruction of Proto-Nostratic
The following data is taken from Kaiser and Shevoroshkin (1988) and Bengtson (1998) and transcribed into the IPA.
Phonology
The phonemes tabulated below are commonly reconstructed for the Proto-Nostratic language (Kaiser and Shevoroshkin 1988). Allan Bomhard (2008), who relies more heavily on Afroasiatic and Dravidian than on Uralic, as do members of the "Moscow School", reconstructs a different vowel system, with three pairs of vowels represented as: /a/~/ə/, /e/~/i/, /o/~/u/, as well as independent /i/, /o/, and /u/. In the first three pairs of vowels, Bomhard is attempting to specify the subphonemic variation involved, inasmuch as that variation led to some of the vowel gradation (ablaut) and vowel harmony patterning found in various daughter languages.
Consonants
The reconstructed consonants of Nostratic are shown in the table below. Every distinction is supposed to be contrastive by the Nostraticists who reconstruct them.
| Bilabial | Alveolar or dental | Alveolo- palatal |
Post- alveolar |
Palatal | Velar | Uvular | Pharyngeal | Glottal | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| central | lateral | ||||||||||
| Plosive | ejective | pʼ[41] | tʼ | kʼ | qʼ | ʔ | |||||
| voiceless | p | t | k | q | |||||||
| voiced | b | d | ɡ | ɢ | |||||||
| Affricate | ejective | tsʼ | tɬʼ | tɕʼ[41] | tʃʼ | ||||||
| voiceless | ts | tɬ | tɕ[41] | tʃ | |||||||
| voiced | dz | dɮ[41] | dʑ[41] | dʒ | |||||||
| Fricative | voiceless | s | ɬ | ɕ[41] | ʃ | χ | ħ | h | |||
| voiced | ʁ | ʕ | |||||||||
| Nasal | m | n | nʲ | ŋ | |||||||
| Trill | r | rʲ[41] | |||||||||
| Approximant | l | lʲ | j | w | |||||||
Vowels
|
|
Front | Central | Back |
|---|---|---|---|
| Close | */i/ • */y/[42] | */u/ | |
| Mid | */e/ |
|
*/o/ |
| Near-open | */æ/ |
|
|
| Open | */a/ | ||
Sound correspondences
The following table is compiled from data given by Kaiser and Shevoroshkin (1988) and Starostin.[43] They follow Illich-Svitych's correspondences in which Nostratic voiceless stops give (traditional) PIE voiced ones, and Nostratic glottalized stops give (traditional) PIE voiceless stops,[44] in contradiction with the PIE glottalic theory, which makes traditional PIE voiced stops appear like glottalized ones. To correct this anomaly, linguists such as Manaster Ramer[45] and Bomhard[46] have proposed to correlate Nostratic voiceless and glottalized stops with PIE ones, so this is done in the table.
Because linguists working on Proto-Indo-European, Proto-Uralic, and Proto-Dravidian do not usually use the IPA, the transcriptions used in those fields are also given where the letters differ from the IPA symbols. The IPA symbols are between slashes because this is a phonemic transcription. The exact values of the phoneme "*p₁" in Proto-Afroasiatic and Proto-Dravidian are unknown. "∅" indicates disappearance without a trace. Hyphens indicate different developments at the beginning and in the interior of words; no consonants ever occurred at the ends of word roots. (Starostin's list of affricate and fricative correspondences does not mention Afroasiatic or Dravidian, and Kaiser and Shevoroshkin don't mention these sounds much; hence the holes in the table.)
Note that there are at present several different mutually incompatible reconstructions of Proto-Afroasiatic (see [1] for two recent reconstructions). The one used here has been said to be based too strongly on Proto-Semitic (Yakubovich 1998[47]).
Similarly, the paper by Kaiser and Shevoroshkin is much older than the Etymological Dictionary of the Altaic Languages (2003; see Altaic languages article) and therefore assumes a somewhat different phonological system for Proto-Altaic.
| Consonants | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Proto-Nostratic | Proto-Indo-European | Proto-Kartvelian | Proto-Uralic | Proto-Altaic | Proto-Dravidian | Proto-Afroasiatic | |||
| /p/ | /p/, /b/ | /p/, /b/ | /p/ | /p/ | "p₁"-, -/p/-, /v/- | "p₁"-, -/p/-, -/b/- | |||
| /pʼ/[48] | /p/ | /pʼ/-, /p/- | /p/-, -pp- -/pː/-, -/p/- | /pʰ/-, -/p/-, -/b/- | /b/-, -/p/-, -/v/- | /p/ | |||
| /b/ | bʰ /bʱ/ | /b/ | /p/-, -/w/- | /b/ | /b/-, -/v/-, -/p/- | /b/ | |||
| /m/ | /m/ | /m/ | /m/ | /m/, /b/ | /m/ | /m/ | |||
| /w/ | w/u̯ /w/ | /w/, /u/ | /w/, /u/ | /b/-?, ∅-, -/b/-, -∅-, /u/ | /v/-, ∅-, -/v/- | /w/, /u/ | |||
| /t/ | /d/ | /t/ | /t/ | /d/ | /d/-, -/t/-, -/d/- | /t/ | |||
| /tʼ/ | /t/ | /tʼ/ | /t/-, -tt- -/tː/-, -/t/- | /tʰ/-, -/t/- | /d/-, -/t/-, /d/- | /tʼ/, /t/ | |||
| /d/ | dʰ /dʱ/ | /d/ | /t/-, -ð- -/ð/- | /d/ | /d/-, -ṭ- -/ʈ/-, -ḍ- -/ɖ/- | /d/ | |||
| /ts/ (/tɕ/) | /sk/-, -/s/- | /ts/, /tɕ/ | ć /tɕ/ | /tʃʰ/, -/s/- | -/c/- | -/s/- | |||
| /tsʼ/ (/tɕʼ/) | /sk/-, -/s/- | /tsʼ/, /tɕʼ/ | ć /tɕ/ | /s/ |
|
| |||
| /dz/ (/dʑ/) | /s/ | /dz/, /dʑ/, /z/, /ʑ/ | /s/, ś /ɕ/ | /dʒ/ |
|
/z/- | |||
| /s/ (/ɕ/) | /s/ | /s/, /ɕ/ | /s/, ś /ɕ/ | /s/ | j /ɟ/ | /s/ | |||
| /n/ | /n/ | -/n/- | /n/ | -/n/- | n- /n̪/-, -n- -/n̪/-, -ṉ- -/n̺/- | /n/ | |||
| /nʲ/ | y-/i̯- /j/-, /n/- |
|
ń /nʲ/ | /nʲ/-, -/n/-? | -ṇ-? -/ɳ/ | /n/ | |||
| /r/ (/rʲ/) | /r/ | /r/ | /r/ | /l/-?, -/r/-, /rʲ/ | /n̪/-, -/r/-, -ṟ- -/r̺/-, ṛ /ɻ/ | /r/ | |||
| /tɬ/ | /s/-, -/l/- | /l/ | j- /j/- |
|
|
/tɬ/-, -/l/- | |||
| /ɬ/ | /l/ | /l/ | -x-? -/ɬ/-[49] | /l/ | /d/, /ɭ/ | /l/ | |||
| /l/ | /l/ | /l/ | /l/ | /l/ | n- /n̪/-, -/l/- | /l/ | |||
| /lʲ/ | /l/ | /r/, /l/ | lˈ /lʲ/ | /lʲ/ | ḷ /ɭ/ | /l/ | |||
| /tʃ/ | /st/-, /s/- | /tʃ/ | ć /tɕ/ | /tʃʰ/ |
|
| |||
| /tʃʼ/ | /st/ | /tʃʼ/ | č, š /tʃ/, /ʃ/ | /tʃʰ/-, -/s/- |
|
| |||
| /dʒ/ | /st/ | /dʒ/ | č /tʃ/ | /dʒ/ |
|
| |||
| /ʃ/ | /s/ | /ʃ/ | š /ʃ/ | /s/ | /d/, /ɭ/ |
| |||
| /j/ | y/i̯ /j/ | /j/ | /j/- | /j/ | y /j/ | /j/ | |||
| /k/ | /ɡ/, ǵ /ɡʲ/, gʷ /ɡʷ/[50] | /k/ | /k/ | /k/-, -/ɡ/- | /ɡ/-, -/k/-, -/ɡ/- | /k/ | |||
| /kʼ/ | /k/, ḱ /kʲ/, kʷ /kʷ/[50] | /kʼ/ | /k/-, -kk- -/kː/-, -/k/- | /kʰ/-, -/k/- | /ɡ/-, -/k/-, -/ɡ/- | /kʼ/ | |||
| /ɡ/ | gʰ /ɡʱ/, ǵʰ /ɡʲʱ/, gʰʷ /ɡʷʱ/[50] | /ɡ/ | /k/-, -x- -/ʁ/-[49] | /ɡ/ | /ɡ/-, -∅- | /ɡ/ | |||
| /ŋ/ | -/n/- | -/m/-? | /ŋ/ | -/nʲ/- | n- /n̪/-, -ṉ- -/n̺/-, -/t/- | -/n/- | |||
| /q/ | h₂ /χ/[49] | /q/ | ∅-, -/k/- | ∅-, -/k/-, -/ɡ/- | ∅-, -/ɡ/- | /χ/ | |||
| /qʼ/ | /k/, ḱ /kʲ/, kʷ /kʷ/[50] | /qʼ/-, -/kʼ/- | /k/-, -kk- -/kː/- | /kʰ/-, -/k/- | /ɡ/-, -/k/-, -/ɡ/- | /kʼ/ | |||
| /ɢ/ | h₃ /ʁ/[49] | /ʁ/ | -x- ∅-, -/ʁ/-[49] | ∅-, -/ɡ/- | ∅ | /ʁ/ | |||
| /χ/ | h₂ /χ/[49] | /χ/ | ∅-, -x- -/ʁ/-?[49] | ∅- | ∅- | /ħ/ | |||
| /ʁ/ | h₃ /ʁ/[49] | /ʁ/ | ∅-, -x- -/ʁ/-?[49] | ∅- | ∅- | /ʕ/ | |||
| /ħ/ | h₁ /h/[49] | /h/ > ∅ | ∅-, -x- -/ʁ/-?[49] | ∅- | ∅- | /ħ/ | |||
| /ʕ/ | h₁ /h/[49] | /h/ > ∅ | ∅-, -x- -/ʁ/-?[49] | ∅- | ∅- | /ʕ/ | |||
| /ʔ/ | h₁ /ʔ/[49] | /h/ > ∅ | ∅ | ∅ | ∅ | /ʔ/ | |||
| /h/ | h₂? /χ/[49] | /h/ > ∅ | ∅-, -x- -/ʁ/-?[49] | ∅- | ∅- | /h/ | |||
| Vowels | |||||||||
| Proto-Nostratic | Proto-Indo-European[51] | Proto-Kartvelian[51] | Proto-Uralic | Proto-Altaic | Proto-Dravidian | Proto-Afroasiatic[51] | |||
| /a/ | /e/, /a/ | /e/ | /a/ | /a/ | /a/ | /a/ ? | |||
| /e/ | /e/, ∅ | /e/, ∅ | /e/ | /e/ | /e/, /i/ |
| |||
| /i/ | /ai̯/, /e/, /ei̯/, /i/, ∅ | /e/, /i/, ∅ | /i/ | /i/ | /i/ | /i/ ? | |||
| /o/ | /e/, /o/ | /we/ ~ /wa/ | /o/ | /o/ | /o/, /a/ |
| |||
| /u/ | /au̯/, /e/, /eu̯/, /u/ | /u/ ~ /wa/ | /u/ | /u/ | /u/, /o/ | /u/ ? | |||
| /æ/ | /e/ | /e/, /a/, /aː/ | /æ/ | ä /æ/ | /a/ |
| |||
| /y/ | /e/ | /u/ | /y/, /ø/ | ü /y/ | /u/ |
| |||
Morphology
Because grammar is less easily borrowed than words, grammar is usually considered stronger evidence for language relationships than vocabulary. The following correspondences (slightly modified to account for the reconstruction of Proto-Altaic by Starostin et al. [2003]) have been suggested by Kaiser and Shevoroshkin (1988). /N/ could be any nasal consonant. /V/ could be any vowel. (The above cautionary notes on Afroasiatic and Dravidian apply.)
| Proto-Nostratic | Proto-Indo-European | Proto-Kartvelian | Proto-Uralic | Proto-Altaic | Proto-Dravidian | Proto-Afroasiatic |
|---|---|---|---|---|---|---|
| Noun affixes | ||||||
| /na/ "originally a locative particle"[52] | /en/ 'in' | /nu/, /n/[53] | -/na/ | -/na/ |
|
-/n/ |
| /Na/ or /Næ/ "animate plural" |
|
-/(e)n/ | -/NV/² |
|
|
-/aːn/ |
| -/tʼV/ "inanimate plural"[54] | [55] | -/t/- | -/t/ | -/tʰ/- |
|
-/æt/ |
| -/kʼa/ "diminutive" | -/k/- | -/akʼ/-, -/ikʼ/ | -kka -/kːa/, -kkä -/kːæ/ | -/ka/ | [56] |
|
| Verb affixes | ||||||
| /s(V)/ "causative-desiderative" | -/se/- | -/su/, -/sa/ |
|
|
-ij -/iɟ/- | /ʃV/-, -/ʃ/- |
| /tʼV/- "causative-reflexive" |
|
|
-t(t)- -/t(ː)/- | -/t/-[57] | -/t/- | /tV/- |
| Particles | ||||||
| /mæ/ "prohibitive" | mē /meː/ | /maː/, /moː/ |
|
/mæ/, /bæ/ | /ma/- | /m(j)/ |
| /kʼo/ "intensifying and copulative" | -/kʷe/ 'and'[58] | /kwe/ | -/ka/, -kä -/kæ/ | -/ka/ |
|
/k(w)/ |
In addition, Kaiser and Shevoroshkin[59] write the following about Proto-Nostratic grammar (two asterisks are used for reconstructions based on reconstructions; citation format changed):
The verb stood at the end of the sentence (SV and SOV type). The 1st p[er]s[on] was formed by adding the 1st ps. pronoun **mi to the verb; similarly, the 2nd ps. was formed by adding **ti. There were no endings for the 3rd ps. present [or at least none can be reconstructed], while the 3rd ps. preterit ending was **-di (Illich-Svitych 1971, pp. 218–19). Verbs could be active and passive, causative, desiderative, and reflective; and there were special markers for most of these categories. Nouns could be animate or inanimate, and plural markers differed for each category. There were subject and object markers, locative and lative enclitic particles, etc. Pronouns distinguished direct and oblique forms, animate and inanimate categories, notions of the type 'near':'far', inclusive:exclusive [...], etc. Apparently there were no prefixes. Nostratic words were either equal to roots or built by adding endings or suffixes. There are some cases of word composition...
Lexicon
According to Dolgopolsky, Proto-Nostratic language had analytic structure, which he argues by diverging of post- and prepositions of auxiliary words in descendant languages. Dolgopolsky states three lexical categories to be in the Proto-Nostratic language:
- Lexical words
- Pronouns
- Auxiliary words
Word order was subject–object–verb when the subject was a noun, and object–verb–subject when it was a pronoun. Attributive (expressed by a lexical word) preceded its head. Pronominal attributive ('my', 'this') might follow the noun. Auxiliary words are considered to be postpositions.
Personal pronouns
Personal pronouns are seldom borrowed between languages. Therefore the many correspondences between Nostratic pronouns are rather strong evidence for the existence of a Proto-Nostratic language. The difficulty of finding Afroasiatic cognates is, however, taken by some as evidence that Nostratic has two or three branches, Afroasiatic and Eurasiatic (and possibly Dravidian), and that most or all of the pronouns in the following table can only be traced to Proto-Eurasiatic.
Nivkh is a living (if moribund) language with an orthography, which is given here. /V/ means that it is not clear which vowel should be reconstructed.
For space reasons, Etruscan is not included, but the fact that it had /mi/ 'I' and /mini/ 'me' seems to fit the pattern reconstructed for Proto-Nostratic ideally, leading some[60] to argue that the Aegean or Tyrsenian languages were yet another Nostratic branch.
There is no reconstruction of Proto-Eskimo–Aleut, although the existence of the Eskimo–Aleut family is generally accepted.[61]
|
|
Proto- Nostratic |
Proto- Indo- European |
Proto- Uralic |
Proto- Altaic |
Proto- Kartvelian |
Proto- Dravidian |
Proto- Yukaghir |
Nivkh | Proto- Chukotko- Kamchatkan |
Proto- Eskimo |
Proto- Afro- Asiatic |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 'I' (nominative) |
/mi/ | h₁eǵom /ʔeɡʲom/[note 1] |
/mi/ | /bi/ | /me/, /mi/ |
|
/met/ | ни /ni/ | [note 1] | /wi/ ˈIˈ, -/ˈˈˈmˈˈˈkət/ ˈI [act on] theeˈ | /mi/,[note 2] -/mi/[note 3] |
| 'me' ~ 'mine' (oblique cases) |
/minV/ | /mene/[note 4] | /minV/- | /mine/- | /men/- |
|
|
|
[note 1] |
|
|
| 'thou' (nominative) |
/tʼi/ and/or /si/ |
ti ~ tū /ti/ ~ /tuː/ |
/ti/ | /tʰi/ and/or /si/ |
|
[note 5] | /tet/ | тъи, чи /tʰi/, /t͡ʃi/ |
/tu/ | /ci/[note 6] | /t(i)/ |
| 'thee' (oblique) | /tʼinV/ and/or /sinV/ |
te- /te/- | tū- /tuː/- | /tʰin/- and/or /sin/- |
/si/-, /se/- |
|
|
|
|
-/mkəˈˈˈtˈˈˈ/ ˈI [act on] theeˈ |
|
| 'we' (inclusive) | /mæ/ | /we/-, -/me/- 'we' | mä- ~ me- /mæ/- ~ /me/- 'we' | /ba/(nom.) /myn/- (oblique) 'we' |
/men/-, /m/- | ma ~ mā /ma/ ~ /maː/ 'we' |
/mit/ 'we' |
мер /mer/[62] 'we' |
/mur/ 'we' |
|
/m(n)/[note 2] |
| 'we' (exclusive) | /na/ | /ne/- 'we'[note 7] |
|
|
/naj/, /n/-[note 8] | nām /naːm/ 'we' |
|
|
|
|
/naħnu/[note 9] |
| 'you' (plural) | /tʼæ/ | -/te/[note 10] | tä /tæ/ | /tʰV/ and/or /sV/ |
|
|
/tit/ |
|
/tur/ |
|
?/t(V)/ |
Other words
Below are selected reconstructed etymologies from Kaiser and Shevoroshkin (1988) and Bengtson (1998). Reconstructed ( = unattested) forms are marked with an asterisk. /V/ means that it is not clear which vowel should be reconstructed. Likewise, /E/ could have been any front vowel and /N/ any nasal consonant. Only the consonants are given of Proto-Afroasiatic roots (see above).
- Proto-Nostratic */kʼo/ or */qʼo/ 'who'
- Proto-Indo-European *kʷo- /kʷo/- 'who', kʷi- /kʷi/- (with suffix -i-) 'what'. Ancestors of the English wh- words.
- Proto-Afroasiatic */kʼ(w)/ and /k(w)/ 'who'. The change from ejective to plain consonants in Proto-Afroasiatic is apparently regular in grammatical words (Kaiser and Shevoroshkin 1988; see also */tV/ instead of */tʼV/ above).
- Proto-Altaic ?*/kʰa/-. The presence of /a/ instead of /o/ is unexplained, but Kaiser and Shevoroshkin (1988) regard this alternation as common among Nostratic languages.
- Proto-Uralic *ko- ~ ku- /ko/- ~ /ku/- 'who'
- "Yukaghir" (Northern, Southern, or both?) кин /kin/ 'who'
- Proto-Chukotko-Kamchatkan */mki/, */mkin/- 'who'
- Proto-Eskimo–Aleut */ken/ 'who'
- Proto-Nostratic */kʼærd/, */kʼerd/, or */kʼird/
'heart ~ chest' (Kaiser and Shevoroshkin [1988]; the Proto-Eskimo form
given by Bengtson [1998] may indicate that the vowel was /æ/ or not).
- Proto-Indo-European *ḱerd- /kʲerd/- 'heart'. The occurrence of *d instead of *dʰ is regular: voiceless and aspirated consonants never occur together in the same Proto-Indo-European root.
- Afroasiatic: Proto-Chadic */kʼVrd/- 'chest'
- Proto-Kartvelian */mkʼerd-/ (/m/ being a prefix) 'chest ~ breast'
- Proto-Eskimo */qatə/ 'heart ~ breast'. The presence of /q/ instead of /k/ is not clear.
- Proto-Turkic */køky-rʲ/ - 'chest'[63]
- Proto-Nostratic */qʼiwlV/ 'ear ~ hear'
- Proto-Indo-European *ḱleu̯- /kʲleu̯/- 'hear'. Ancestor of English listen, loud.
- Proto-Afroasiatic */kʼ(w)l/ 'hear'
- Proto-Kartvelian */qʼur/ 'ear'
- Proto-Altaic */kʰul/- 'ear'
- Proto-Uralic *kūle- /kuːle/- (long vowel from fusion of -/iw/-) 'hear'
- Proto-Dravidian *kēḷ /keːɭ/ 'hear'. (Must figure out if it's /g/- instead.)
- Proto-Chukotko-Kamchatkan */vilvV/, possibly from earlier /kʷilwV/ 'ear'
- Proto-Nostratic */kiwæ/ ~ /kiwe/ ~ /kiwi/ 'stone'
- Afroasiatic: Proto-Chadic */kw/- 'stone'
- Proto-Kartvelian */kwa/- 'stone'
- Proto-Uralic *kiwe- /kiwe/- 'stone'
- Proto-Dravidian */kwa/ 'stone'
- Proto-Chukotko-Kamchatkan */xəvxə/ 'stone'; Kamchadal квал /kβal/, ков /koβ/ 'stone'
- Proto-Eskimo–Aleut */kew/- 'stone'
- Proto-Nostratic */wete/ 'water'
- Proto-Indo-European *wed- /wed/- 'water ~ wet'
- Altaic: Proto-Tungusic */ødV/ 'water'
- Proto-Uralic *wete /wete/ 'water'
- Proto-Dravidian *ōtV- ~ wetV- /oːtV/- ~ /wetV/- 'wet'
- Proto-Nostratic */burV/ 'storm'
- Proto-Indo-European *bʰer- /bʱer/- 'storm'
- Proto-Afroasiatic (?) */bwr/- 'storm'
- Proto-Altaic */burV/ ~ /borV/ 'storm'
- Proto-Uralic *purki /purki/- 'snow storm ~ smoke' (-/k/- unexplained)
- Proto-Nostratic */qantʼV/ 'front side'
- Proto-Indo-European *h₂ant- /χant/- 'front side'
- Proto-Afroasiatic */χnt/ 'front side'; the change from */ntʼ/ to */nt/ is apparently regular
- Proto-Altaic */antV/- 'front side'
- Proto-Nostratic */d͡zeɢV/ 'eat'
- Proto-Indo-European *seh₃(w)- /seʁ(w)/- 'satiated'
- Proto-Afroasiatic (?) */zʁ/- 'be fed' ~ 'be abundant'
- Proto-Kartvelian */d͡zeʁ/- 'become sated'
- Proto-Altaic */d͡ʒeː/ 'eat'
- Proto-Uralic *sexi- /seʁi/- or *sewi- /sewi/- 'eat'
- Proto-Nostratic */nʲamo/ 'grasp'
- Proto-Indo-European *i̯em- /jem/- 'grasp'
- Proto-Dravidian *ñamV- /ɲamV/- 'grasp'
- Proto-Nostratic */ʔekh₁-/ 'to move quickly, to rage; to be furious, raging, violent, spirited, fiery, wild (of a horse)'
- Proto-Indo-European */h₁ek-u-/ 'quick, swift (of a horse)'
- Proto-Altaic */èk`á/ 'to paw, hit with hooves; to move quickly, to rage (of a horse)'
- Proto-Nostratic */kʼutʼV/ 'little'
- Proto-Afroasiatic */kʼ(w)tʼ/ ~ /k(w)tʼ/ ~ /kt/ 'little'
- Proto-Kartvelian */kʼutʼ/ ~ /kʼotʼ/ 'little'
- Proto-Dravidian *kuḍḍ- /kuɖː/- 'little'. (Must figure out if plosives correct.)
- Proto-Turkic */küčük/-g from Proto-Altaic */k`ič`V/ ( ~ -č-)[64]
Sample text
In the 1960s, Vladislav Illich-Svitych composed a brief poem using his version of Proto-Nostratic.[65] (Compare Schleicher's fable for similar attempts with several different reconstructions of Proto-Indo-European.)
| Nostratic (Illich-Svitych's spelling) | Nostratic (IPA) | Russian | English | Finnish |
|---|---|---|---|---|
| K̥elHä wet̥ei ʕaK̥un kähla | /KʼelHæ wetʼei ʕaKʼun kæhla/ | Язык – это брод через реку времени, | Language is a ford through the river of time, | Kieli on kahluupaikka ajan joen yli, |
| k̥aλai palhʌ-k̥ʌ na wetä | /kʼat͡ɬai palhVkʼV na wetæ/ | он ведёт нас к жилищу умерших; | it leads us to the dwelling of those gone before; | se johdattaa meidät kuolleiden kylään; |
| śa da ʔa-k̥ʌ ʔeja ʔälä | /ɕa da ʔakʼV ʔeja ʔælæ/ | но туда не сможет дойти тот, | but he cannot arrive there, | mutta ei voi tulla sinne se, |
| ja-k̥o pele t̥uba wete | /jakʼo pele tʼuba wete/ | кто боится глубокой воды. | who fears deep water. | joka pelkää syvää vettä. |
The value of K̥ or Kʼ is uncertain—it could be /kʼ/ or /qʼ/. H could similarly be at least /h/ or /ħ/. V or ʌ is an uncertain vowel.
Status within comparative linguistics
While the Nostratic hypothesis is not endorsed by the mainstream of comparative linguistics, Nostratic studies by nature of being based on the comparative method remain within the mainstream of contemporary linguistics from a methodological point of view; it is the scope with which the comparative method is applied rather than the methodology itself that raises eyebrows.[citation needed]
Nostraticists tend to refuse to include in their schema language families for which no proto-language has yet been reconstructed. This approach was criticized by Joseph Greenberg on the ground that genetic classification is necessarily prior to linguistic reconstruction,[66] but this criticism has so far had no effect on Nostraticist theory and practice.
Certain critiques have pointed out that the data from individual, established language families that is cited in Nostratic comparisons often involves a high degree of errors; Campbell (1998) demonstrates this for Uralic data. Defenders of the Nostratic theory argue that were this to be true, it would remain that in classifying languages genetically, positives count for vastly more than negatives (Ruhlen 1994). The reason for this is that, above a certain threshold, resemblances in sound/meaning correspondences are highly improbable mathematically.
Pedersen's original Nostratic proposal synthesized earlier macrofamilies, some of which, including Indo-Uralic, involved extensive comparison of inflections.[67] It is true the Russian Nostraticists and Bomhard initially emphasized lexical comparisons. Bomhard recognized the necessity to explore morphological comparisons and has since published extensive work in this area (see especially Bomhard 2008:1.273–386). According to him the breakthrough came with the publication of the first volume of Joseph Greenberg's Eurasiatic work,[68] which provided a massive list of possible morphemic correspondences that has proved fruitful to explore.[69] Other important contributions on Nostratic morphology have been published by John C. Kerns[70] and Vladimir Dybo.[71]
Critics argue that were one to collect all the words from the various known Indo-European languages and dialects which have at least one of any 4 meanings, one could easily form a list that would cover any conceivable combination of two consonants and a vowel (of which there are only about 20×20×5 = 2000). Nostraticists respond that they do not compare isolated lexical items but reconstructed proto-languages. To include a word for a proto-language it must be found in a number of languages and the forms must be relatable by regular sound changes. In addition, many languages have restrictions on root structure, reducing the number of possible root-forms far below its mathematical maximum. These languages include, among others, Indo-European, Uralic, and Altaic—all the core languages of the Nostratic hypothesis. To understand how the root structures of one language relate to those of another has long been a focus of Nostratic studies.[72] For a highly critical assessment of the work of the Moscow School, especially the work of Illich-Svitych, cf. Campbell and Poser 2008:243-264. Campbell and Poser argue that Nostratic, as reconstructed by Illich-Svitych and others, is "typologically flawed". For instance, they point out that, surprisingly, very few Nostratic roots contain two voiceless stops, which are less marked and should therefore occur more frequently, and where such roots do occur, in almost all cases the second stop occurs after a sonorant.[73] In summary, Campbell and Poser reject the Nostratic hypothesis and, as a parting shot, state that they "seriously doubt that further research will result in any significant support for this hypothesized macro-family."[74]
It has also been argued that Nostratic comparisons mistake Wanderwörter and cross-borrowings between branches for true cognates.[75]
See also
Notes
- Verb suffix.
References
On the other hand, Comrie baldly states, in answer to his own question of the relatedness of Altaic, Uralic and Indo-European pronominal systems, 'I do not know'. Other agnostics represented in this volume, such as Ringe, Vine, Campbell, and even Hamp, demonstrate that the hypothesis is being taken seriously indeed by skeptics specializing in Indo-European and Uralic, at least. While these scholars seek to test the hypothesis, Nostratic has been around long enough and has been discussed widely enough that some regard the genetic affiliations as established.
The Nostratic theory is among the most promising of the many currently controversial theories of linguistic classification. It remains the best-argued of all the solutions hitherto presented for the affiliations of the languages of northern Eurasia, a problem that goes back to the German Franz Bopp and the Dane Rasmus Rask, two of the founders of Indo-European studies.
In general, Nostratic studies have failed to meet the same methodological standards as Indo-European studies, but then again so have most non-Indo-European studies.
- For example:
From Bomhard and Kerns, The Nostratic Macrofamily, p. 219:
- Proto-Nostratic *bar-/*bər- 'seed, grain':
- A. Proto-Indo-European *b[h]ars- 'grain': Latin far 'spelt, grain'; Old Icelandic barr 'barley'; Old English bere 'barley'; Old Church Slavonic brašъno 'food'. Pokorny 1959:111 *bhares- 'barley'; Walde 1927–1932. II:134 *bhares-; Mann 1984–1987:66 *bhars- 'wheat, barley'; Watkins 1985:5–6 *bhares- (*bhars-) 'barley'; Gamkrelidze-Ivanov 1984.II: 872–873 *b[h]ar(s)-.
- B. Proto-Afroasiatic *bar-/*bər- 'grain, cereal': Proto-Semitic *barr-/*burr 'grain, cereal' > Hebrew bar 'grain'; Arabic burr 'wheat'; Akkadian burru 'a cereal'; Sabaean brr 'wheat'; Harsūsi berr 'corn, maize, wheat'; Mehri ber 'corn, maize, wheat'. Cushitic: Somali bur 'wheat'. (?) Proto-Southern Cushitic *bar-/*bal- 'grain (generic) > Iraqw balaŋ 'grain'; Burunge baru 'grain'; Alagwa balu 'grain' K'wadza balayiko 'grain'. Ehret 1980:338.
- C. Dravidian: Tamil paral 'pebble, seed, stone of fruit'; Malayalam paral 'grit, coarse grain, gravel, cowry shell'; Kota parl 'pebble, one grain (of any grain)'; Kannaḍa paral, paral 'pebble, stone' Koḍagu para 'pebble'; Tuḷu parelụ 'grain of sand, grit, gravel, grain of corn, etc.; castor seed'; Kolami Parca 'gravel'. Burrow-Emeneau 1984:353, no. 3959.
- D. Sumerian bar 'seed'.
- Proto-Nostratic *bar-/*bər- 'seed, grain':
Bibliography
- Baldi, Philip (2002). The Foundations of Latin. Berlin: Mouton de Gruyter.
- Bengtson, John D. (1998). "The 'Far East' of Nostratic". Mother Tongue Newsletter 31:35–38 (image files)
- Bomhard, Allan R., and John C. Kerns (1994). The Nostratic Macrofamily: A Study in Distant Linguistic Relationship. Berlin, New York, and Amsterdam: Mouton de Gruyter. ISBN 3-11-013900-6
- Bomhard, Allan R. (1996). Indo-European and the Nostratic Hypothesis. Signum Publishers.
- Bomhard, Allan R. (2008). Reconstructing Proto-Nostratic: Comparative Phonology, Morphology, and Vocabulary, 2 volumes. Leiden: Brill. ISBN 978-90-04-16853-4
- Bomhard, Allan R. (2008). A Critical Review of Dolgopolsky's Nostratic Dictionary.
- Bomhard, Allan R. (2008). The Glottalic Theory of Proto-Indo-European and Consonantism and Its Implications for Nostratic Sound Correspondences. Mother Tongue.
- Bomhard, Allan R. (2011). The Nostratic Hypothesis in 2011: Trends and Issues. Washington, DC: Institute for the Study of Man. ISBN (paperback) 978-0-9845383-0-0
- Bomhard, Allan R. (2018). A Comprehensive Introduction to Nostratic Comparative Linguistics: With Special Reference to Indo-European. Four volumes, 2,807 pages, combined into a single PDF; published as an open-access book under a Creative Commons license.
- Bomhard, Allan R., (December 2020). A Critical Review of Illič-Svityč's Nostratic Dictionary. Published as an open-access book under a Creative Commons license.
- Campbell, Lyle (1998). "Nostratic: a personal assessment". In Joseph C. Salmons and Brian D. Joseph (eds.), Nostratic: Sifting the Evidence. Current Issues in Linguistic Theory 142. John Benjamins.
- Campbell, Lyle, and William J. Poser (2008). Language Classification: History and Method. Cambridge: Cambridge University Press.
- Campbell, Lyle (2004). Historical Linguistics: An Introduction (2nd ed.). Cambridge: The MIT Press.
- Cuny, Albert (1924). Etudes prégrammaticales sur le domaine des langues indo-européennes et chamito-sémitiques. Paris: Champion.
- Cuny, Albert (1943). Recherches sur le vocalisme, le consonantisme et la formation des racines en « nostratique », ancêtre de l'indo-européen et du chamito-sémitique. Paris: Adrien Maisonneuve.
- Cuny, Albert (1946). Invitation à l'étude comparative des langues indo-européennes et des langues chamito-sémitiques. Bordeaux: Brière.
- Dolgopolsky, Aharon (1998). The Nostratic Macrofamily and Linguistic Paleontology. McDonald Institute for Archaeological Research. ISBN 978-0-9519420-7-9
- Dolgopolsky, Aharon (2008). Nostratic Dictionary. McDonald Institute for Archaeological Research. [2]
- Dybo, Vladimir (2004). "On Illič-Svityč's study ‘Basic Features of the Proto-Language of the Nostratic Language Family'." In Nostratic Centennial Conference: The Pécs Papers, edited by Irén Hegedűs and Paul Sidwell, 115-119. Pécs: Lingua Franca Group.
- Flannery, Kent V. (1969). In: P. J. Ucko and G. W. Dimbleby (eds.), The Domestication and Exploitation of Plants and Animals 73-100. Aldine, Chicago, IL.
- Gamkrelidze, Thomas V., and Vjačeslav V. Ivanov (1995). Indo-European and the Indo-Europeans, translated by Johanna Nichols, 2 volumes. Berlin and New York: Mouton de Gruyter. ISBN 3-11-014728-9
- Greenberg, Joseph (2000, 2002). Indo-European and its Closest Relatives. The Eurasiatic Language Family. (Stanford University), v.1 Grammar, v.2 Lexicon.
- Greenberg, Joseph (2005). Genetic Linguistics: Essays on Theory and Method, edited by William Croft. Oxford: Oxford University Press.
- Illich-Svitych, V. M. В. М. Иллич-Свитыч (1971-1984). Опыт сравнения ностратических языков (семитохамитский, картвельский, индоевропейский, уральский, дравидийский, алтайский). Введение. Сравнительный словарь. 3 vols. Moscow: Наука.
- Kaiser, M.; Shevoroshkin, V. (1988). "Nostratic". Annu. Rev. Anthropol. 17: 309–329. doi:10.1146/annurev.an.17.100188.001521.
- Kaiser, M. (1989). "Remarks on Historical Phonology: From Nostratic to Indo-European" Archived 2012-03-05 at the Wayback Machine. Reconstructing Languages and Cultures BPX 20:51-56.
- Manaster Ramer, Alexis (?). A "Glottalic" Theory of Nostratic Archived 2012-03-05 at the Wayback Machine.
- Norquest, Peter (1998). "Greenberg's Visit to Arizona". Mother Tongue Newsletter 31:25f. (image files)
- Renfrew, Colin (1991). "Before Babel: Speculations on the Origins of Linguistic Diversity". Cambridge Archaeological Journal. 1 (1): 3–23. doi:10.1017/S0959774300000238. S2CID 161811559.
- Renfrew, Colin, and Daniel Nettle, editors (1999). Nostratic: Examining a Linguistic Macrofamily. McDonald Institute for Archaeological Research. ISBN 978-1-902937-00-7
- Ruhlen, Merritt (1991). A Guide to the World's Languages, Volume 1: Classification. Edward Arnold. ISBN 0-340-56186-6
- Ruhlen, Merritt (1994). On the Origin of Languages: Studies in Linguistic Taxonomy. Stanford, California: Stanford University Press.
- Ruhlen, Merritt (1998). "Toutes parentes, toutes différentes". La Recherche 306:69–75. (French translation of a Scientific American article.)
- Ruhlen, Merritt (2001). "Taxonomic Controversies in the Twentieth Century". In: Jürgen Trabant and Sean Ward (eds.), New Essays on the Origin of Language 197–214. Berlin: Mouton de Gruyter.
- Salmons, Joseph C., and Brian D. Joseph, editors (1998). Nostratic: Sifting the Evidence. John Benjamins. ISBN 1-55619-597-4
- Stachowski, Marek, "Teoria nostratyczna i szkoła moskiewska".(pdf) – LingVaria 6/1 (2011): 241-274
- Starostin, Georgiy S. (1998). "Alveolar Consonants in Proto-Dravidian: One or More?". (pdf) Pages 1–14 (?) in Proceedings on South Asian languages
- Starostin, Georgiy S. (2002). "On the Genetic Affiliation of the Elamite Language". (pdf) Mother Tongue 7.
- Starostin, George; Kassian, Alexei; Trofimov, Artem; Zhivlov, Mikhail. 2017. 400-item basic wordlist for potentially "Nostratic" languages. Moscow: Laboratory for Oriental and Comparative Studies of the School of Advanced Studies in the Humanities, Russian Presidential Academy.
- Sweet, Henry (1900, 1995, 2007). The History of Language. ISBN 81-85231-04-4 (1995); ISBN 1-4326-6993-1 (2007)
- Szemerényi, Oswald (1996). Introduction to Indo-European Linguistics. Oxford: Oxford University Press.
- Trask, R. L. (1996). Historical Linguistics. New York: Oxford University Press.
- Yakubovich, I. (1998). Nostratic studies in Russia
Further reading
- Hage, Per. “On the Reconstruction of the Proto-Nostratic Kinship System”. In: Zeitschrift Für Ethnologie 128, no. 2 (2003): 311–25. http://www.jstor.org/stable/25842921.
- Manaster Ramer, Alexis (1993). “On Illič-Svityč's Nostratic Theory”. In: Studies in Language 17: 205—250
- WITCZAK K.T., KOWALSKI A.P. (2012). "Nostratyka. Wspólnota językowa indoeuropejska". In: Przeszłość społeczna. Próba konceptualizacji, red. S. Tabaczyński i in. (red.), Poznań, pp. 826–837.
External links
- Stefan Georg, 2013, Review of Salmons & Joseph, eds, Nostratic: Sifting the Evidence, 1997
- "Linguists debating deepest roots of language" – New York Times article on Nostratic (June 27, 1995)
- "What is Nostratic?" by John Bengtson, in Mother Tongue Newsletter 31 (1998), pages 33–38
- "Nostraticist Vladislav Markovich Illich-Svitych" – photograph, Nostratic poem (2002)
- Proposed descent tree for Borean languages, including Nostratic by Sergei Starostin
- Database query to Nostratic etymology on StarLing database (last modified 2006)
- Nostratic Dictionary by Aharon Dolgopolsky (2006): main page at Cambridge University DSpace and "Preface" by Colin Renfrew
| Authority control: National |
|---|
https://en.wikipedia.org/wiki/Nostratic_languages
| Borean | |
|---|---|
| (hypothetical) | |
| Geographic distribution | Eurasia, sometimes the Americas |
| Linguistic classification | Proposed language family |
| Proto-language | Proto-Borean language |
| Subdivisions |
|
| Glottolog | None |
 Borean macro-family according to Sergei Starostin | |
Borean (also Boreal or Boralean)[1] is a hypothetical linguistic macrofamily that encompasses almost all language families worldwide except those native to the Americas, Africa, Oceania, and the Andaman Islands. Its supporters propose that the various languages spoken in Eurasia and adjacent regions have a genealogical relationship, and ultimately descend from languages spoken during the Upper Paleolithic in the millennia following the Last Glacial Maximum. The name Borean is based on the Greek βορέας, and means "northern". This reflects the fact that the group is held to include most language families native to the northern hemisphere. Two distinct models of Borean exist: that of Harold C. Fleming and that of Sergei Starostin.
Fleming's model
The concept is due to Harold C. Fleming (1987), who proposed such a "mega-super-phylum" for the languages of Eurasia, termed Borean or Boreal in Fleming (1991) and later publications. In Fleming's model, Borean includes ten different groups: Afrasian (his term for Afroasiatic), Kartvelian, Dravidian, a group comprising Sumerian, Elamitic, and some other extinct languages of the ancient Near East, Eurasiatic (a proposal of Joseph Greenberg that includes Indo-European, Uralic, Altaic, and several other language families), Macro-Caucasian (a proposal of John Bengtson that includes Basque and Burushaski), Yeniseian, Sino-Tibetan, Na-Dene, and Amerind.[2]
Harold C. Fleming, in 2002, argued that there were not a two large super-phyla distinction between a Nostratic and a Dené–Caucasian taxon among Borean languages, and that the language kinship between its branches is possibly more complex than a Nostratic versus a Dené–Caucasian super-phyla.[2]
However, in 2013, Harold C. Fleming had changed his view about this issue in a joint article with Stephen L. Zegura, James B. Harrod, John D. Bengtson and Shomarka O.Y. Keita - "The Early Dispersions of Homo Sapiens sapiens and proto-Human from Africa." in Mother Tongue (journal), issue XVIII, p. 143-188, 2013, where he argues that Nostratic and Dene-Caucasian as language phyla within Borean is a hypothesis that is well grounded and convincing.
Fleming writes that his work on Borean is inspired by Joseph Greenberg's exploration of Eurasiatic, and is oriented towards the concept of "valid taxon". He rejects Nostratic, a proposed macrofamily somewhat broader than Eurasiatic, and withholds judgment on Dené–Caucasian, a proposal that would encompass Sino-Tibetan, Yeniseian, Basque, and several other language families and isolates. Fleming calls Borean a "phyletic chain" rather than a super-phylum. He notes that his model of Borean is similar to Morris Swadesh's Vasco-Dene proposal, although he also sees similarities between Vasco-Dene and Dené–Caucasian. He sees Borean as closely associated with the appearance of the Upper Paleolithic in the Levant, Europe, and western Eurasia from 50 thousand to 45 thousand years ago, and observes that it is primarily associated with human populations of Caucasoid and Northern Mongoloid physical appearance, the exceptions being southern India, southern China, southwestern Ethiopia, northern Nigeria, and the Chad Republic.[2]
The phylogenetic composition of Borean (noncommital about higher linkages within the whole) according to Fleming, Bengtson, Zegura, Harrod, and Keita (2013)[3] is as follows:
- "Borean" (Phyletic Chain)[4]
- (1)
- c) (2) (strongly different languages between themselves and aberrant in its relationship to the other Borean phyla and language families)[6]
- a) (3)
- b) (4)
- d) (5)
- e) (6)
- Vasco-Caucasic (Vasco-Caucasian) (based on a John Bengtson proposal)
- f) (7)
- g) (8)
- h) (9)
- i) (10)
- Amerind (outlined by Joseph Greenberg) (a valid taxon with large contrasts among sub-taxa)
- Austric (not included in Borean) (Fleming et al.[3] are not sure if it is or not more closely related to Borean, that is, if Borean and Austric have an Austric-Borean common ancestor or if Austric is not closer to Borean than to other major language super-phyla)
Starostin's model

As envisaged by Sergei Starostin (2002), Borean is divided into two groups, Nostratic (sensu lato, consisting of Eurasiatic and Afroasiatic) and Dene–Daic, the latter consisting of the Dené–Caucasian and Austric macrofamilies.[8] Starostin tentatively dates the Borean proto-language to the Upper Paleolithic, approximately 16 thousand years ago. Starostin's model of Borean would thus include most languages of Eurasia, as well as the Afroasiatic languages of North Africa and the Horn of Africa, and the Eskimo–Aleut and the Na-Dene languages of the New World.
Murray Gell-Mann, Ilia Peiros, and Georgiy Starostin maintain that the comparative method has provided strong evidence for some linguistic superfamilies (Dené-Caucasian and Eurasiatic), but not so far for others (Afroasiatic and Austric). Their view is that since some of these families have not yet been reconstructed and others still require improvement, it is impossible to apply the strict comparative method to even older and larger groups. However, they consider this only a technical rather than a theoretical problem, and reject the idea that linguistic relationships further back in time than 10,000 years before the present cannot be reconstructed, since the "main objects of research in this case are not modern languages, but reconstructed proto-languages which turn out to be more similar to one another than their modern day descendants".[1] They believe that good reconstructions of superfamilies such as Eurasiatic will eventually help in investigating still deeper linguistic relationships. While such 'ultra-deep' relationships can currently be discussed only on a speculative level, they maintain that the numerous morphemic similarities between language families of Eurasia, many of which Sergei Starostin compiled into a special database that he later supplemented by his own findings, are unlikely to be due to chance, making it possible to formulate a Borean super-superfamily hypothesis.[9]
They have also suggested possible links between 'Borean' and other families. In their view comparisons with 'Borean' data suggest that Khoisan cannot be included within it but that more distant connections on an even deeper level might be possible, that how the African superfamilies Niger–Congo, East Sudanic, Central Sudanic and Kordofanian are related to Borean remains to be investigated, that the situation with the native languages of the Americas remains unresolved, and that while there are some lexical similarities between Borean and the Trans–New Guinea languages, these remain too scarce to establish a firm connection. They comment that while preliminary data indicates possible connections between Borean and some superfamilies from Africa, the Americas, and the Indo-Pacific region further research is needed to determine whether these additional superfamilies are related to Borean or unidentified branches of it.[9] Gell-Mann et al. note that their proposed model of Borean differs significantly from that of Fleming.[9]
Sergei Starostin died prematurely in 2005 and his hypothesis remains in a preliminary form, with much of the material he collected available online.[10][11]
The phylogenetic composition of Borean according to Starostin is as follows:
- "Borean"
- Nostratic (speculative, Holger Pedersen 1903)
- Indo-Uralic (speculative, Joseph Greenberg 2000)
- Indo-European (widely recognized family)
- Altaic (widely rejected; Roy Andrew Miller 1971, Gustaf John Ramstedt 1952, Matthias Castrén 1844)
- Uralic (widely recognized family)
- Yukaghir (language isolate)
- Paleosiberian (phylogenetic unity widely rejected)
- Eskimo–Aleut (widely recognized family)
- Chukotko-Kamchatkan (widely recognized family)
- Sumerian (language isolate)
- Elamite (language isolate)
- Kartvelian (widely recognized family)
- Dravidian (widely recognized family)
- Afroasiatic (widely recognized family)
- Indo-Uralic (speculative, Joseph Greenberg 2000)
- Dene–Daic (speculative, Starostin 2005)
- Dené–Caucasian (speculative, Nikolayev 1991; expanded by Bengtson 1997), cf. Dené–Yeniseian (Edward Vajda 2008)
- Yeniseian (widely recognized family)
- Na-Dené (widely recognized family)
- Iberian (language isolate)
- Basque (language isolate)
- Sino-Caucasian (speculative, Starostin 2006)
- Sino-Tibetan (widely recognized family)
- Burushaski (language isolate)
- North Caucasian (widely recognized family)
- Hattic (language isolate)
- Hurro-Urartian (widely recognized family)
- Austric (speculative, Wilhelm Schmidt 1906)
- Austro-Tai (speculative, Paul Benedict 1942)
- Austronesian (widely recognized family)
- Tai–Kadai (widely recognized family)
- Hmong–Mien (widely recognized family)
- Austroasiatic (widely recognized family)
- Austro-Tai (speculative, Paul Benedict 1942)
- Dené–Caucasian (speculative, Nikolayev 1991; expanded by Bengtson 1997), cf. Dené–Yeniseian (Edward Vajda 2008)
- Nostratic (speculative, Holger Pedersen 1903)
Jäger (2015)
A computational phylogenetic analysis by Jäger (2015) did not support the Borean macrophylum in its entirety, but provided the following phylogeny of language families in Eurasia:[12]
|
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Other languages
Sumerian
Allan Bomhard argues that Sumerian did not descend from a daughter language of Proto-Nostratic but from a sister language of it. In other words, Sumerian descended from an older common ancestor language with Proto-Nostratic and did not descend directly from it; that is, Sumerian was closer to Nostratic but not a member of it.[13]
Kartvelian
Bomhard argues that Kartvelian is closer to Eurasiatic than to other language families within Nostratic and that the differences are due to the fact that Kartvelian became separated from Eurasiatic at a very early date.[13]
Status of the hypothesis
Linguist Asya Pereltsvaig states in Languages of the World: An Introduction that both versions of the Borean hypothesis are "controversial and tentative".[14]
See also
Notes
- Pereltsvaig, Asya (2012-02-09). Languages of the World: An Introduction. Cambridge University Press. ISBN 9781107002784.
References
- H. C. Fleming, 'A New Taxonomic Hypothesis: Borean or Boralean', Mother Tongue 14 (1991).
- H. C. Fleming, 'Proto-Gongan Consonant Phonemes: Stage One', in Mukarovsky (ed.) FS Reinisch (1987), 141-159.
External links
https://en.wikipedia.org/wiki/Borean_languages
| Proto-Human | |
|---|---|
| Proto-Sapiens, Proto-World | |
| (disputed, hypothetical) | |
| Reconstruction of | All extant languages |
| Era | Paleolithic |
The Proto-Human language (also Proto-Sapiens, Proto-World) is the hypothetical direct genetic predecessor of all the world's spoken languages.[1] It would not be ancestral to sign languages.[2]
The concept is speculative and not amenable to analysis in historical linguistics. It presupposes a monogenetic origin of language, i.e. the derivation of all natural languages from a single origin, presumably at some time in the Middle Paleolithic period. As the predecessor of all extant languages spoken by modern humans (Homo sapiens), Proto-Human language as hypothesised would not necessarily be ancestral to any hypothetical Neanderthal language.
Terminology
There is no generally accepted term for this concept. Most treatments of the subject do not include a name for the language under consideration (e.g. Bengtson and Ruhlen[3]). The terms Proto-World and Proto-Human[4] are in occasional use. Merritt Ruhlen used the term Proto-Sapiens.
History of the idea
The first serious scientific attempt to establish the reality of monogenesis was that of Alfredo Trombetti, in his book L'unità d'origine del linguaggio, published in 1905.[5]: 263 [6] Trombetti estimated that the common ancestor of existing languages had been spoken between 100,000 and 200,000 years ago.[7]: 315
Monogenesis was dismissed by many linguists in the late 19th and early 20th centuries, when the doctrine of the polygenesis of the human races and their languages was widely popularised.[8]: 190
The best-known supporter of monogenesis in America in the mid-20th century was Morris Swadesh.[5]: 215 He pioneered two important methods for investigating deep relationships between languages, lexicostatistics and glottochronology.
In the second half of the 20th century, Joseph Greenberg produced a series of large-scale classifications of the world's languages. These were and are controversial but widely discussed. Although Greenberg did not produce an explicit argument for monogenesis, all of his classification work was geared toward this end. As he stated:[9]: 337 "The ultimate goal is a comprehensive classification of what is very likely a single language family."
Notable American advocates of linguistic monogenesis include Merritt Ruhlen, John Bengtson, and Harold Fleming.
Date and location
The first concrete attempt to estimate the date of the hypothetical ancestor language was that of Alfredo Trombetti,[7]: 315 who concluded it was spoken between 100,000 and 200,000 years ago, or close to the first emergence of Homo sapiens.
It is uncertain or disputed whether the earliest members of Homo sapiens had fully developed language. Some scholars link the emergence of language proper (out of a proto-linguistic stage that may have lasted considerably longer) to the development of behavioral modernity toward the end of the Middle Paleolithic or at the beginning of the Upper Paleolithic, roughly 50,000 years ago. Thus, in the opinion of Richard Klein, the ability to produce complex speech only developed some 50,000 years ago (with the appearance of modern humans or Cro-Magnons). Johanna Nichols (1998)[10] argued that vocal languages must have begun diversifying in our species at least 100,000 years ago.
In 2011, an article in the journal Science proposed an African origin of modern human languages.[11] It was suggested that human language predates the out-of-Africa migrations of 50,000 to 70,000 years ago and that language might have been the essential cultural and cognitive innovation that facilitated human colonization of the globe.[12]
In Perreault and Mathew (2012),[13] an estimate on the time of the first emergence of human language was based on phonemic diversity. This is based on the assumption that phonemic diversity evolves much more slowly than grammar or vocabulary, slowly increasing over time (but reduced among small founding populations). The largest phoneme inventories are found among African languages, while the smallest inventories are found in South America and Oceania, some of the last regions of the globe to be colonized. The authors used data from the colonization of Southeast Asia to estimate the rate of increase in phonemic diversity. Applying this rate to African languages, Perreault and Mathew (2012) arrived at an estimated age of 150,000 to 350,000 years, compatible with the emergence and early dispersal of H. sapiens. The validity of this approach has been criticized as flawed.[14]
Characteristics
Speculation on the "characteristics" of Proto-World is limited to linguistic typology, i.e. the identification of universal features shared by all human languages, such as grammar (in the sense of "fixed or preferred sequences of linguistic elements"), and recursion, but beyond this nothing can be known of it.[15]
Christopher Ehret has hypothesized that Proto-Human had a very complex consonant system, including clicks.[16]
A few linguists, such as Merritt Ruhlen, have suggested the application of mass comparison and internal reconstruction (cf. Babaev 2008). A number of linguists have attempted to reconstruct the language, while many others[who?] reject this as fringe science.[17]
Vocabulary
Ruhlen tentatively traces a number of words back to the ancestral language, based on the occurrence of similar sound-and-meaning forms in languages across the globe. Bengtson and Ruhlen identify 27 "global etymologies".[3] The following table lists a selection of these forms:[18]
| Language phylum |
Who? | What? | Two | Water | One / Finger | Arm-1 | Arm-2 | Bend / Knee | Hair | Vulva / Vagina | Smell / Nose |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Khoisan | !kū | ma | /kam | k´´ā | //kɔnu | //kū | ≠hā | //gom | /ʼū | !kwai | č’ū |
| Nilo-Saharan | na | de | ball | nki | tok | kani | boko | kutu | sum | buti | čona |
| Niger–Congo | nani | ni | bala | engi | dike | kono | boko | boŋgo | butu |
| |
| Afroasiatic | k(w) | ma | bwVr | ak’wa | tak | ganA | bunqe | somm | put | suna | |
| Kartvelian | min | ma | yor | rts’q’a | ert | t’ot’ | qe | muql | toma | putʼ | sun |
| Dravidian | yāv | yā | iraṇṭu | nīru | birelu | kaŋ | kay | meṇḍa | pūṭa | počču | čuṇṭu |
| Eurasiatic | kwi | mi | pālā | akwā | tik | konV | bhāghu(s) | bük(ä) | punče | p’ut’V | snā |
| Dené–Caucasian | kwi | ma | gnyis | ʔoχwa | tok | kan | boq | pjut | tshām | putʼi | suŋ |
| Austric | o-ko-e | m-anu | ʔ(m)bar | namaw | ntoʔ | xeen | baγa | buku | śyām | betik | iǰuŋ |
| Indo-Pacific | mina | boula | okho | dik | akan | ben | buku | utu | sɨnna | ||
| Australian | ŋaani | minha | bula | gugu | kuman | mala | pajing | buŋku | puda | mura | |
| Amerind | kune | mana | p’āl | akwā | dɨk’i | kano | boko | buka | summe | butie | čuna |
| Source:.[18]: 103 The symbol V stands for "a vowel whose precise character is unknown" (ib. 105). | |||||||||||
Based on these correspondences, Ruhlen[18]: 105 lists these roots for the ancestor language:
- ku = 'who'
- ma = 'what'
- pal = 'two'
- akwa = 'water'
- tik = 'finger'
- kanV = 'arm'
- boko = 'arm'
- buŋku = 'knee'
- sum = 'hair'
- putV = 'vulva'
- čuna = 'nose, smell'
The full list of Bengtson's and Ruhlen's (1994) 27 "global etymologies" is given below.[3]
No. Root Gloss 1 aja ‘mother, older female relative’ 2 bu(n)ka ‘knee, to bend’ 3 bur ‘ashes, dust’ 4 čun(g)a ‘nose; to smell’ 5 kama ‘hold (in the hand)’ 6 kano ‘arm’ 7 kati ‘bone’ 8 k’olo ‘hole’ 9 kuan ‘dog’ 10 ku(n) ‘who?’ 11 kuna ‘woman’ 12 mako ‘child’ 13 maliq’a ‘to suck(le), nurse; breast’ 14 mana ‘to stay (in a place)’ 15 mano ‘man’ 16 mena ‘to think (about)’ 17 mi(n) ‘what?’ 18 pal ‘two’ 19 par ‘to fly’ 20 poko ‘arm’ 21 puti ‘vulva’ 22 teku ‘leg, foot’ 23 tik ‘finger; one’ 24 tika ‘earth’ 25 tsaku ‘leg, foot’ 26 tsuma ‘hair’ 27 ʔaq’wa ‘water’
Syntax
There are competing theories about the basic word order of the hypothesized Proto-Human. These usually assume subject-initial ordering because it is the most common globally. Derek Bickerton proposes SVO (subject-verb-object) because this word order (like its mirror OVS) helps differentiate between the subject and object in the absence of evolved case markers by separating them with the verb.[19]
By contrast, Talmy Givón hypothesizes that Proto-Human had SOV (subject-object-verb), based on the observation that many old languages (e.g., Sanskrit, Latin) had dominant SOV, but the proportion of SVO has increased over time. On such a basis, it is suggested that human languages are shifting globally from the original SOV to the modern SVO. Givón bases his theory on the empirical claim that word-order change mostly results in SVO and never in SOV.[20]
Exploring Givón's idea in their 2011 paper, Murray Gell-Mann and Merritt Ruhlen stated that shifts to SOV are also attested. However, when these are excluded, the data indeed support Givón's claim. The authors justified the exclusion by pointing out that the shift to SOV is unexceptionally a matter of borrowing the order from a neighbouring language. Moreover, they argued that, since many languages have already undergone a change to SVO, a new trend towards VSO and VOS ordering has arisen.[21]
Harald Hammarström reanalysed the data. In contrast to such claims, he found that a shift to SOV is in every case the most common type, suggesting that there is, rather, an unchanged universal tendency towards SOV regardless of the way that languages change, and that the relative increase of SVO is a historical effect of European colonialism.[22] In conclusion, it is the best guess that the first language had SOV—because it is generally the most common—but it could have had any set order or no dominant order.
Criticism
Many linguists reject the methods used to determine these forms. Several areas of criticism are raised with the methods Ruhlen and Gell-Mann employ. The essential basis of these criticisms is that the words being compared do not show common ancestry; the reasons for this vary. One is onomatopoeia: for example, the suggested root for 'smell' listed above, *čuna, may simply be a result of many languages employing an onomatopoeic word that sounds like sniffing, snuffling, or smelling. Another is the taboo quality of certain words. Lyle Campbell points out that many established proto-languages do not contain an equivalent word for *putV 'vulva' because of how often such taboo words are replaced in the lexicon, and notes that it "strains credibility to imagine" that a proto-World form of such a word would survive in many languages.
Using the criteria that Bengtson and Ruhlen employ to find cognates to their proposed roots, Lyle Campbell finds seven possible matches to their root for woman *kuna in Spanish, including cónyuge 'wife, spouse', chica 'girl', and cana 'old woman (adjective)'. He then goes on to show how what Bengtson and Ruhlen would identify as reflexes of *kuna cannot possibly be related to a proto-World word for woman. Cónyuge, for example, comes from the Latin root meaning 'to join', so its origin had nothing to do with the word 'woman'; chica is related to a Latin word meaning 'insignificant thing'; cana comes from the Latin word for 'white', and again shows a history unrelated to the word 'woman'.[23] Campbell's assertion is that these types of problems are endemic to the methods used by Ruhlen and others.
There are some linguists who question the very possibility of tracing language elements so far back into the past. Campbell notes that given the time elapsed since the origin of human language, every word from that time would have been replaced or changed beyond recognition in all languages today. Campbell harshly criticizes efforts to reconstruct a Proto-human language, saying "the search for global etymologies is at best a hopeless waste of time, at worst an embarrassment to linguistics as a discipline, unfortunately confusing and misleading to those who might look to linguistics for understanding in this area."[24]
See also
- Adamic language
- Borean languages
- Linguistic universals
- List of languages by first written accounts
- List of proto-languages
- Origin of language
- Origin of speech
- Polygenesis (linguistics)
- Proto-language
- Recent African origin of modern humans
- Universal grammar
References
Notes
The Proto-World language, also known as the Proto-Human or Proto-Sapiens, is believed to be the single source of origin of all the world's languages.
Bowern, Claire (November 2011). "Out of Africa? The logic of phoneme inventories and founder effects". Linguistic Typology. 15 (2): 207–216. doi:10.1515/lity.2011.015. hdl:1885/28291. ISSN 1613-415X. S2CID 120276963.
- Campbell & Poser (2008:393)
Sources
- Bengtson, John D. 2007. "On fossil dinosaurs and fossil words". (Also: HTML version.)
- Campbell, Lyle, and William J. Poser. 2008. Language Classification: History and Method. Cambridge: Cambridge University Press.
- Edgar, Blake (March–April 2008). "Letter from South Africa". Archaeology. 61 (2). Retrieved 5 November 2018.
- Gell-Mann, Murray and Merritt Ruhlen. 2003. "The origin and evolution of syntax"[dead link]. (Also: HTML version[dead link].)
- Givón, Talmy. 1979. On Understanding Grammar. New York: Academic Press.
- Greenberg, Joseph. 1963. "Some universals of grammar with particular reference to the order of meaningful elements". In Universals of Language, edited by Joseph Greenberg, Cambridge: MIT Press, pp. 58–90. (In second edition of Universals of Language, 1966: pp. 73–113.)
- Greenberg, Joseph H. 1966. The Languages of Africa, revised edition. Bloomington: Indiana University Press. (Published simultaneously at The Hague by Mouton & Co.)
- Greenberg, Joseph H. 1971. "The Indo-Pacific hypothesis". Reprinted in Joseph H. Greenberg, Genetic Linguistics: Essays on Theory and Method, edited by William Croft, Oxford: Oxford University Press, 2005.
- Greenberg, Joseph H. 2000–2002. Indo-European and Its Closest Relatives: The Eurasiatic Language Family. Volume 1: Grammar. Volume 2: Lexicon. Stanford: Stanford University Press.
- Klein, Richard G. and Blake Edgar. 2002. The Dawn of Human Culture. New York: John Wiley and Sons.
- McDougall, Ian; Brown, Francis H.; Fleagle, John G. (2005). "Stratigraphic placement and age of modern humans from Kibish, Ethiopia" (PDF). Nature. 433 (7027): 733–736. Bibcode:2005Natur.433..733M. doi:10.1038/nature03258. PMID 15716951. S2CID 1454595.
- Nandi, Owi Ivar. 2012. Human Language Evolution, as Coframed by Behavioral and Psychological Universalisms, Bloomington: iUniverse Publishers.
- Wells, Spencer. 2007. Deep Ancestry: Inside the Genographic Project. Washington, D.C.: National Geographic.
- White, Tim D.; Asfaw, B.; DeGusta, D.; Gilbert, H.; Richards, G.D.; Suwa, G.; Howell, F.C. (2003). "Pleistocene Homo sapiens from Middle Awash, Ethiopia". Nature. 423 (6941): 742–747. Bibcode:2003Natur.423..742W. doi:10.1038/nature01669. PMID 12802332. S2CID 4432091.
External links
- "Genetic Distance and Language Affinities Between Autochthonous Human Populations"
- Babaev, Kirill. 2008. "Critics of the Nostratic theory", in Nostratica: Resources on Distant Language Relationship.
https://en.wikipedia.org/wiki/Proto-Human_language
The Dolgopolsky list is a word list compiled by Aharon Dolgopolsky in 1964.[1] It lists the 15 lexical items that have the most semantic stability, i.e. they are the 15 words least likely to be replaced[why?] by other words as a language evolves. It was based on a study of 140 languages from across Eurasia.
List
The words, with the first being the most stable, are:
- I/me
- two/pair
- you (singular, informal)
- who/what
- tongue
- name
- eye
- heart
- tooth
- no/not
- nail (finger-nail)
- louse/nit
- tear/teardrop
- water
- dead
The first item in the list, I/me, has been replaced in none of the 140 languages during their recorded history; the fifteenth, dead, has been replaced in 25% of the languages.
The twelfth item, louse/nit, is well kept in the North Caucasian languages, Dravidian and Turkic, but not in some other proto-languages.
See also
References
- Dolgopolsky, Aharon B. 1964. Gipoteza drevnejšego rodstva jazykovych semej Severnoj Evrazii s verojatnostej točky zrenija [A probabilistic hypothesis concerning the oldest relationships among the language families of Northern Eurasia]. Voprosy Jazykoznanija 2: 53-63.
- Trask, Robert Lawrence (2000). The dictionary of historical and comparative linguistics. p. 96.
External links
https://en.wikipedia.org/wiki/Dolgopolsky_list
An etymological dictionary discusses the etymology of the words listed. Often, large dictionaries, such as the Oxford English Dictionary and Webster's, will contain some etymological information, without aspiring to focus on etymology.
Etymological dictionaries are the product of research in historical linguistics. For many words in any language, the etymology will be uncertain, disputed, or simply unknown. In such cases, depending on the space available, an etymological dictionary will present various suggestions and perhaps make a judgement on their likelihood, and provide references to a full discussion in specialist literature.
The tradition of compiling "derivations" of words is pre-modern, found for example in Indian (nirukta), Arabic (al-ištiqāq) and also in Western tradition (in works such as the Etymologicum Magnum and Isidore of Seville's Etymologiae). Etymological dictionaries in the modern sense, however, appear only in the late 18th century (with 17th-century predecessors such as Vossius' 1662 Etymologicum linguae Latinae or Stephen Skinner's 1671 Etymologicon Linguae Anglicanae), with the understanding of sound laws and language change and their production was an important task of the "golden age of philology" in the 19th century.
- English
- Robert K. Barnhart & Sol Steinmetz, eds. Barnhart Dictionary of Etymology. Bronx, NY: H. W. Wilson, 1988 (reprinted as Chambers Dictionary of Etymology).
- Terry F. Hoad. The Concise Oxford Dictionary of English Etymology. Oxford: Oxford University Press, 1986.
- Ernest Klein. A Comprehensive Etymological Dictionary of the English Language. 2 vols. Amsterdam: Elsevier, 1966-67.
- C.T. Onions, ed. The Oxford Dictionary of English Etymology. Oxford: Oxford University Press, 1966.
- Eric Partridge, Origins: A short etymological dictionary of Modern English. New York: Greenwich House, 1958 (reprint: 1959, 1961, 1966, 2008).
- Albanian
- Kolec Topalli. Fjalor etimologjik i gjuhës shqipe. Durrës: Jozef, 2017.
- Vladimir Orel. Albanian Etymological Dictionary. Leiden: Brill, 1998.
- Eqrem Çabej. Studime etimologjike në fushë të shqipes. 7 vols. Tirana: Akademia et Shkencave e Republikës Popullore të Shqipërisë, Instituti i Gjuhësisë dhe i Letërsisë, 1976–2014.
- Armenian
- Hrachia Acharian. Հայերեն արմատական բառարան [Dictionary of Armenian Root Words]. 4 vols. Yerevan: Yerevan State University, 1971.
- Guevorg Djahukian. Հայերեն ստուգաբանական բառարան, [Armenian Etymological Dictionary]. Yerevan: International Linguistic Academy, 2010.
- Hrach K. Martirosyan. Etymological dictionary of the Armenian inherited lexicon. Leiden, Boston: Brill, 2010.
- Breton
- Albert Deshayes. Dictionnaire étymologique du breton. Douarnenez: Le Chasse-Marée, 2003.
- Chinese
- Axel Schuessler. ABC Etymological Dictionary of Old Chinese. Honolulu: University of Hawaii Press, 2007.
- Czech
- Holub, J., Kopečný, F. Etymologický slovník jazyka českého. Prague: Státní nakladatelství učebnic (1952) [1933]
- Machek, Václav. Etymologický slovník jazyka českého. Prague: NLN, Nakladatelství Lidové noviny (2010 [1971]) [1957]
- Holub, J. & S. Lyer. Stručný etymologický slovník jazyka českého se zvláštním zřetelem k slovům kulturním a cizím. Prague: SPN (1992) [1967]
- Rejzek, Jiří. Český etymologický slovník. Voznice: LEDA (2012 [2001])
- Danish
- Edwin Jessen (1893), Dansk etymologisk Ordbog (in Danish), Copenhagen: Gyldendal, Wikidata Q65525361
- Jan Katlev, ed. (2000), Politikens Etymologisk Ordbog. Danske ords historie (in Danish), Copenhagen: Politikens Forlag, Wikidata Q110820320
- Dutch
- Marlies Philippa, Frans Debrabandere, A. Quak, T. Schoonheim, & Nicoline van der Sijs, eds. Etymologisch woordenboek van het Nederlands (EWN). 4 vols. Amsterdam: Amsterdam University Press, 2003–09.
- Jan de Vries. Nederlands etymologisch woordenboek (NEW), 4th edn. Leiden: Brill, 1997 (1st edn. 1971).
- Finnish
- Suomen sanojen alkuperä [The Origin of Finnish Words]. 3 vols. Helsinki: Kotimaisten kielten tutkimuskeskus / Suomalaisen Kirjallisuuden Seura, 1992–2000 (vol. 1, A–K 1992; vol. 2, L–P 1995; vol. 3, R–Ö 2000).
- French
- Alain Rey, ed. Dictionnaire historique de la langue française, 4th edn. 2 vols. Paris: Le Robert, 2016 (1st edn. 1992).
- Emmanuèle Baumgartner & Philippe Ménard. Dictionnaire étymologique et historique de la langue française. Paris: Livre de Poche, 1996.
- Jacqueline Picoche. Dictionnaire étymologique du français. Paris: Le Robert, 1971.
- Albert Dauzat, Jean Dubois, & Henri Mitterand. Nouveau dictionnaire étymologique et historique, 2nd edn. Paris: Larousse, 1964 (1st edn. 1938).
- Oscar Bloch & Walther von Wartburg. Dictionnaire étymologique de la langue française, 2nd edn. Paris: PUF, 1950 (1st edn. 1932).
- Walther von Wartburg & Hans-Erich Keller, eds. Französisches etymologisches Wörterbuch: Eine Darstellung des gallormanischen Sprachschatzes (FEW). 25 vols. Bonn: Klopp; Heidelberg: Carl Winter; Leipzig–Berlin: Teubner; Basel: R. G. Zbinden, 1922–67 (some vols. have since been revised).
- German
- Elmar Seebold, ed. Etymologisches Wörterbuch der deutschen Sprache [ Etymological Dictionary of the German Language ], 26th edn. Originally by Friedrich Kluge. Berlin: Walter de Gruyter, 2013 (1st edn. 1883).
- Wolfgang Pfeifer, ed. Etymologisches Wörterbuch des Deutschen, 7th edn. Munich: dtv, 2004 (1st edn., 1995).
- Gunther Drosdowsi, Paul Grebe, et al., eds. Duden, Das Herkunftswörterbuch: Etymologie der deutschen Sprache, 5th edn. Berlin: Duden, 2013.
- Sabine Krome, ed. Wahrig, Herkunftswörterbuch, 5th edn. Originally by Ursula Hermann. Gütersloh–Munich: Wissenmedia, 2009.
- Greek
- Georgios Babiniotis. Ετυµολογικό λεξικό της νέας ελληνικής γλώσσας [= Etymological Dictionary of the Modern Greek Language]. 2 vols. Athens: Κέντρο λεξικογραφίας, 2010.
- Ancient Greek
- Robert S. P. Beekes. Etymological Dictionary of Greek. 2 vols. Leiden: Brill, 2010.
- Pierre Chantraine. Dictionnaire étymologique de la langue grecque: Histoire des mots, revised 2nd edn. 2 vols. Revised by Jean Taillardat, Olivier Masson, & Jean-Louis Perpillou. Paris: Klincksieck, 2009 (2nd edn. 1994; 1st edn. 1968–80 in 4 vols.).
- Hjalmar Frisk. Griechisches etymologisches Wörterbuch. 3 vols. Heidelberg: Carl Winter, 1960–72.
- Georgios Babiniotis. Ετυµολογικό λεξικό της νέας ελληνικής γλώσσας [= Etymological Dictionary of the Modern Greek Language]. 2 vols. Athens: Κέντρο λεξικογραφίας, 2010.
- Hittite
- Alwin Kloekhorst. Etymological Dictionary of the Hittite Inherited Lexicon. Leiden–Boston: Brill, 2008.
- Jaan Puhvel. Hittite Etymological Dictionary. 10 vols. Berlin: Mouton de Gruyter, 1984–present.
- Hungarian
- Gábor Zaicz. Etimológiai szótár: Magyar szavak és toldalékok eredete (‘Dictionary of Etymology: The origin of Hungarian words and affixes’), 2nd edn. Budapest: Tinta Könyvkiadó, 2021 (1st edn., 2006)
- András Róna-Tas & Árpád Berta. West Old Turkic: Turkic Loanwords in Hungarian. 2 vols. Wiesbaden: Harrassowitz, 2011.
- István Tótfalusi. Magyar etimológiai nagyszótár. Budapest: Arcanum Adatbázis, 2001.
- Icelandic
- Italian
- Alberto Nocentini. L’Etimologico: vocabolario della lingua italiana. With the collaboration of Alessandro Parenti. Milan: Mondadori, 2010.
- Manlio Cortelazzo & Paolo Zolli. Dizionario etimologico della lingua italiana (DELIN), 2nd edn. Bologna: Zanichelli, 2004 (1st edn. 5 vols., 1979-1988).
- Latin
- Michiel de Vaan. Etymological Dictionary of Latin and the Other Italic Languages. Leiden: Brill, 2008.
- Alois Walde. Lateinisches etymologisches Wörterbuch, 3rd edn. 2 vols. Revised by Johann Baptist Hofmann. Heidelberg: Carl Winter, 1938–54 (1st edn. 1906).
- Alfred Ernout & Antoine Meillet. Dictionnaire étymologique de la langue latine: Histoire des mots (DELL), 4th rev. edn. 2 vols. Revised by Jacques André. Paris: Klincksieck, 1985 (4th edn. 1959–60; 1st edn. 1932).
- Latvian
- Konstantīns Karulis. Latviešu Etimoloģijas Vārdnīca. Rīga: Avots, 1992.
- Lithuanian
- Ernst Fraenkel, Annemarie Slupski, Erich Hofmann, & Eberhard Tangl, eds. Litauisches etymologisches Wörterbuch (LitEW). 2 vols. Heidelberg: Carl Winter; Göttingen: Vandenhoeck & Ruprecht, 1962–65.
- Wolfgang Hock et al. Altlitauisches etymologisches Wörterburch (ALEW). 3 vols. Hamburg: Baar Verlag, 2015.
- Old Church Slavonic
- Etymologický slovník jazyka staroslověnského (ESJS). 21 vols. Prague: Academia, 1989–2022. ISBN 80-200-0222-7.
- Old Irish
- Sanas Cormaic, encyclopedic dictionary, 9th or 10th century
- Joseph Vendryes, E. Bachellery, & Pierre-Yves Lambert. Lexique étymologique de l'irlandais ancien (LÉIA). 7 vols. Dublin: Dublin Institute for Advanced Studies; Paris: CNRC Éditions, 1959–1996 (incomplete).
- Old Prussian
- Vytautas Mažiulis, Prūsų kalbos etimologijos žodynas (1988–1997), Vilnius.
- Polish
- Aleksander Brückner. Słownik etymologiczny języka polskiego, 2nd edn. Warsaw: Wiedza Powszechna, 1957 (reprint 2000; 1st edn. Kraków: Krakowska Spółka Wydawnicza, 1927).
- Kazimierz Rymut. Nazwiska Polaków: słownik historyczno-etymologiczny. 2 vols. Kraków: Wydawn. Instytutu Języka Polskiego PAN, 1999/2001.
- Andrzej Bańkowski. Etymologiczny słownik języka polskiego. 2 vols. Warsaw: Wydawnictwo Naukowe PWN; Częstochowa: Linguard, 2000 (incomplete).
- Krystyna Długosz-Kurczabowa. Nowy słownik etymologiczny języka polskiego. Warsaw: Wydawnictwo Naukowe PWN, 2003.
- Wiesław Boryś. Słownik etymologiczny języka polskiego. Kraków: Wydawnictwo Literackie, 2005.
- Izabela Malmor. Słownik etymologiczny języka polskiego. Warsaw: ParkEdukacja, 2009.
- Portuguese
- José Pedro Machado. Dicionário etimológico da língua portuguesa, 3rd edn. 5 vols. Lisbon: Livros Horizonte, 1977 (1st edn. 1952).
- Antonio Geraldo da Cunha. Dicionário etimológico da língua portuguesa, 4th edn. Revised by Cláudio Mello Sobrinho. Rio de Janeiro: FAPERJ/Lexikon, 2010 (1st edn. 1982).
- Russian
- Pavel Yakovlevich Chernykh. Историко-этимологический словарь современного русского языка. 2 vols. Moscow: Русский язык. 1993.
- Vladimir Orel. Russian Etymological Dictionary. 4 vols. Edited by Vitaly Shevoroshkin & Cindy Drover-Davidson. Calgary, Canada: Octavia Press (vols. 1-3) & Theophania Publishing (vol. 4), 2007-2011.
- Max Vasmer. Russisches etymologisches Wörterbuch. 3 vols. Heidelberg: Carl Winter, 1953-58. (Translated into Russian and expanded by Oleg Trubachov, Этимологический словарь русского языка. 4 vols. Moscow: Прогресс, 1959-1961.)
- Terence Wade. Russian Etymological Dictionary. Bristol: Bristol Classical Press, 1996.
- Sanskrit
- Manfred Mayrhofer. Kurzgefaßtes etymologisches Wörterbuch des Altindischen (KEWA). 3 vols. Heidelberg: Carl Winter, 1956–1976.
- Manfred Mayrhofer. Etymologisches Wörterbuch des Altindoarischen (EWAia). 3 vols. Heidelberg: Carl Winter, 1992/1998/2001.
- Sardinian
- Max Leopold Wagner. Dizionario etimologico sardo (DES). 2 vols. Revised by Giulio Paulis. Nuoro: Ilisso, 2008 (1st edn. 3 vols., Heidelberg: Carl Winter, 1960–4).
- Massimo Pittau. Dizionario della lingua sarda fraseologico ed etimologico (DILS). 2 vols. Cagliari: E. Gasperini, 2000–03.
- Scots
- John Jamieson, An Etymological Dictionary of the Scottish Language (1808), revised 1879–97.
- Serbo-Croatian
- Marta Bjeletić et al. Етимолошки речник српског језика. 3 vols. (А–Бј). Beograd: Srpska akademija nauka i umetnosti, 2003–.
- Alemko Gluhak. Hrvatski etimološki rječnik. Zagreb: August Cesarec, 1993.
- Ranko Matasović, Tijmen Pronk, Dubravka Ivšić, Dunja Brozović Rončević. Etimološki rječnik hrvatskoga jezika. 2 vols. Zagreb: Institut za hrvatski jezik i jezikoslovlje, 2016–21.
- Petar Skok. Etimologijski rječnik hrvatskoga ili srpskoga jezika [Etymological Dictionary of the Croatian or Serbian Language]. 4 vols. Zagreb: Jugoslavenska akademija znanosti i umjetnosti, 1971–4.
- Slovene
- France Bezlaj. Etimološki slovar slovenskega jezika. Ljubljana: SAZU, 1977. (ISBN 86-11-14125-3), COBISS 10028033
- Marko Snoj. Slovenski etimološki slovar. Ljubljana: Založba Modrijan, 2003. (ISBN 961-6465-37-6), COBISS 124973312
- Spanish
- Joan Corominas. Diccionario crítico etimológico castellano e hispánico (DCECH). 6 vols. Madrid: Gredos, 1980–91 (ISBN 84-249-1362-0)
- Guido Gómez de Silva. Elsevier's Concise Spanish Etymological Dictionary. Amsterdam–NY: Elsevier Sciences, 1985. (ISBN 968-16-2812-8)
- Michel Bénaben. Dictionnaire étymologique de l'espagnol. Paris: Ellipses, 2000.
- Edward A. Roberts. A Comprehensive Etymological Dictionary of the Spanish Language with Families of Words Based on Indo-European Roots, 2 vols. (vol. 1: A-G; 2: H-Z). Xlibris, 2014.[self-published source]
- Swedish
- Elof Hellquist. Svensk etymologisk ordbok. Lund: Gleerups, 1922-1980. (ISBN 91-40-01978-0)
- Birgitta Ernby. Norstedts etymologiska ordbok. Stockholm: Norstedts Förlag, 2008. (ISBN 978-91-7227-429-7)
- Turkish
- Sevan Nişanyan. Sözlerin soyağacı: çağdaş Türkçenin etimolojik sözlüğü. Beyoğlu (Istanbul): Adam, 2002.
- Gerard Leslie Makins Clauson. An Etymological Dictionary of Pre-Thirteenth-Century Turkish. London: Oxford University Press, 1972.
Language families
- Afro-Asiatic
- Vladimir Orel & Olga V. Stolbova. Hamito-Semitic Etymological Dictionary: Materials for a Reconstruction. Leiden: Brill, 1995.
- Altaic
- Sergei Starostin, Anna Dybo, & Oleg Mudrak. Etymological Dictionary of the Altaic Languages. Leiden: Brill, 2003.
- Celtic
- Ranko Matasović. Etymological dictionary of Proto-Celtic. Leiden: Brill, 2009.
- Dravidian
- Thomas D. Burrows & Murray Barnson Emeneau. A Dravidian Etymological Dictionary (DED), 2nd edn. Oxford: Munshirm Manoharlal / Clarendon Press, 1984 (1st edn. 1961).
- Germanic
- Guus Kroonen. Etymological Dictionary of Proto-Germanic. Leiden: Brill, 2013.
- Vladimir Orel. A Handbook of Germanic Etymology. Leiden: Brill, 2003.
- Frank Heidermanns. Etymologisches Wörterbuch der germanischen Primäradjektive (EWgA). Berlin: Walter de Gruyter, 1993.
- Proto-Indo-European
- George E. Dunkel. Lexikon der indogermanischen Partikeln und Pronominalstämme (LIPP). Heidelberg: Carl Winter, 2014.
- Dagmar S. Wodtko, Britta Irslinger, & Carolin Schneider. Nomina im indogermanischen Lexikon (NIL). Heidelberg: Carl Winter, 2008.
- Helmut Rix. Lexikon der indogermanischen Verben: Die Wurzeln und ihre Primärstammbildungen (LIV²), 2nd edn. Wiesbaden: Reichert Verlag, 2001.
- Julius Pokorny. Indogermanisches etymologisches Wörterbuch (IEW), 2 vols. Tübingen–Berne–Munich: A. Francke, 1957/1969 (reprint 2005).
- Reworking of: Alois Walde & Julius Pokorny. Vergleichendes Wörterbuch der indogermanischen Sprachen. 3 vols. Berlin: de Gruyter, 1927–32 (reprint 1973).
- Carl Darling Buck. A dictionary of selected synonyms in the principal Indo-European languages. University of Chicago Press, 1949 (paperback edition 1988).
- Slavic
- Rick Derksen. Etymological Dictionary of the Slavic Inherited Lexicon. Leiden: Brill, 2008.
- Etymological Dictionary of Slavic Languages: Proto-Slavic Lexical Stock (ESSJa). 40 vols. (A-*pakъla). Moscow: Nauka, 1974–present.
- Franz Miklosich. Etymologisches Wörterbuch der slavischen Sprachen. Vienna: Wilhelm Braumüller, 1886. 547 pp.
- Uralic
- Károly Rédei, ed. Uralisches etymologisches Wörterbuch (UEW). 3 vols. Budapest: Akadémiai Kiadó; Wiesbaden: Harrassowitz, 1986-91.
Online
Indo-European languages
- [1] – Croatian Language Portal, etymologies by Ranko Matasović
- [2] – An Online Etymological Dictionary of the English language compiled by Douglas Harper
- [3] – Ancient Greek Etymological Dictionary by H. Frisk
- [4] – An Etymological Dictionary of the Hittite Inherited Lexicon by Alwin Kloekhorst
- [5] – Indo-European Etymological Dictionary by S. A. Starostin et al.
- [6] – Gaelic Etymological Dictionary by A. MacBain
- [7] – Gothic Etymological Dictionary by Andras Rajki
- [8] – Nepali Etymological Dictionary by R. L. Turner
- [9] – Romanian Etymological Dictionary
- [10] – Russian Etymological Dictionary by Max Vasmer, Heidelberg (1962), 4 volumes
- [11] – Swedish Etymological Dictionary by Elof Hellquist
Afroasiatic languages
- [12] – Afroasiatic Etymological Dictionary by S. A. Starostin et al.
- [13] – Arabic Etymological Dictionary by Alphaya, LTD
- [14] – Arabic Etymological Dictionary by Andras Rajki
- [15] – Hebrew Etymological Dictionary by Ernest Klein
Altaic languages
- [16] – Altaic Etymological Dictionary by S. A. Starostin et al.
- [17] – Chuvash Etymological Dictionary by M. R. Fedotov
- [18] – Gagauz Etymological Dictionary
- [19] – Mongolian Etymological Dictionary
- [20] – Turkish Etymological Dictionary by Sevan Nişanyan "Sözlerin Soyağacı – Çağdaş Türkçe'nin Etimolojik Sözlüğü" (Third ed. Adam Y. Istanbul 2007)
Austronesian languages
- [21] – Austronesian Comparative Dictionary by R. A. Blust
- [22] – Indonesian Etymological Dictionary by S. M. Zain
- [23] – Maori-Polynesian Comparative Dictionary by E. Tregear
- [24] – A Concise Waray Dictionary (Waray-Waray, Leytese-Samarese) with etymologies and Bicol, Cebuano, Hiligaynon, Ilocano, Kapampangan, Pangasinan and Tagalog cognates
Bantu languages
- [25] – Bantu Etymological Dictionary
- [26] – Swahili Etymological Dictionary
- [27] – Swahili Etymological Dictionary by World Loanword Database
Creole languages and conlangs
- [28] – Bislama Dictionary with etymologies by Andras Rajki
- [29] – Esperanto Etymological Dictionary
- [30] – Morisyen Etymological Dictionary
- [31] – Volapük Dictionary
Uralic languages
- [32] – Uralic Etymological Database (Uralonet)
- [33] – Uralic Etymological Dictionary by S. A. Starostin et al.
- [34] – Estonian Etymological Dictionary by Iris Metsmägi, Meeli Sedrik, Sven-Erik Soosaar
- [35] – Finnish Etymological Dictionary
- [36] – Zaicz, Gábor. Etimológiai szótár: Magyar szavak és toldalékok eredete (’Dictionary of Etymology: The origin of Hungarian words and affixes’). Budapest: Tinta Könyvkiadó, 2006, ISBN 9637094016, first edition.
- Its second, revised, expanded edition published in 2021 is only available in print (ISBN 9789634092926).
- [37] – Tótfalusi, István. Magyar etimológiai nagyszótár (’Hungarian Comprehensive Dictionary of Etymology’). Budapest: Arcanum Adatbázis, 2001; Arcanum DVD Könyvtár, ISBN 9639374121
- [38] – Hungarian Dictionary with etymologies by Andras Rajki
- [39] – Saami Etymological Dictionary
Other languages and language families
- [40] – Etymological Dictionary of Basque by R. L. Trask
- [41] – Basque Etymological Dictionary
- [42] – Dravidian Etymological Dictionary by T. Burrow
- [43] – Kartvelian Etymological Dictionary by G. A. Klimov
- [44] – Mayan Etymological Dictionary by T. Kaufman and J. Justeson
- [45] – Mon-Khmer Etymological Dictionary by D. Cooper and P. J. Sidwell
- [46] – Munda Etymological Dictionary by D. Cooper
- [47] – Munda Etymological Dictionary by D. Stampe et al.
- [48] – North Caucasian Etymological Dictionary by S. A. Starostin et al.
- [49] – Sino-Tibetan Etymological Dictionary and Thesaurus by J. A. Matisoff
- [50] – Thai Etymological Dictionary by M. Haas
See also
External links
- Etymological Bibliography of Take Our Word For It, the only Weekly Word-origin Webzine
- Indo-European Etymological Dictionary (IEED) at Leiden University
- Internet Archive Search: Etymological Dictionary Etymological Dictionaries in English at the Internet archive
- Internet Archive Search: Etymologisches Wörterbuch Etymological Dictionaries in German at the Internet archive
- Online Etymology Dictionary (see also its Wikipedia article)
- Open Directory - Reference: Dictionaries: Etymology at Curlie
| Authority control: National |
|---|
https://en.wikipedia.org/wiki/Etymological_dictionary
 | |
| Author | Sergei Starostin, Anna Dybo, Oleg Mudrak, with assistance of Ilya Gruntov and Vladimir Glumov |
|---|---|
| Published | 2003, Leiden |
| ISBN | 9004131531 |
The Etymological Dictionary of the Altaic Languages is a comparative and etymological dictionary of the hypothetical Altaic language family. It was written by linguists Sergei Starostin, Anna Dybo, and Oleg Mudrak, and was published in Leiden in 2003 by Brill Publishers. It contains 3 volumes, and is a part of the Handbook of Oriental Studies: Section 8, Uralic and Central Asian Studies; no. 8.[1]
The work was sponsored by the Soros Foundation, the Russian Foundation for Basic Research, and the Russian Foundation for Humanities. The work was also supported by Ariel Investments in the Tower of Babel project. All work was conducted within Starostin's STARLING database, available online.[2]: 9
Contents




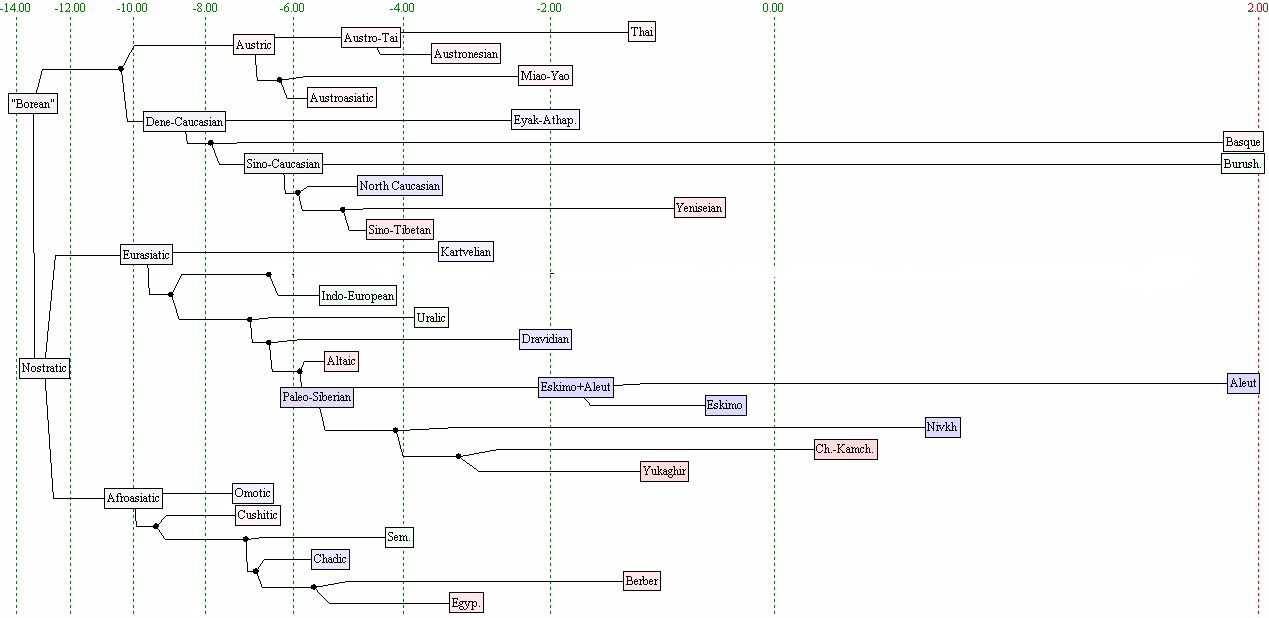{kind=link}
The Etymological Dictionary of the Altaic Languages contains 2,800 etymologies, among which half were newly developed by the team over 10 years.[2]: 8 There is an introduction at the beginning detailing the authors' defenses of the Altaic language family theory. It is claimed that there are two contact zones for the Altaic languages. The first, the Turko-Mongolian Contact, led to many Turkic and Mongolic words being used in both Turkic and Mongolic languages. The authors attempt to explain Turko-Mongolian shared words through loanwords from the 13th century as well as Turkic and Mongolic languages having a common ancestor. The example given is the comparison between Proto-Turkic aŕiga and Middle Mongol ara'a and aral. It is then claimed that the explanation for words with the root ara- being borrowed into Mongolic from Turkic is unsatisfactory, and that the words came from the common Altaic root aŕi, with the suffix -ga.[2]: 13–17 The authors do the same with the Mongol-Tungus Contact, which they also believe the loanword explanation to be insufficient for.[2]: 19
The second chapter of the introduction is a comparative phonology of the Altaic language family. The linguists say that the most common Altaic root structure is CVCV, and compared it with Japanese.[2]: 22 They also reconstructed a consonant system for Altaic, and talk about the Khalaj h-, which yields h- in Khalaj but 0- in other Turkic languages.[2]: 26–27
The dictionary views Altaic as extending to the 5th millennium B.C., and consisting of 3 groups - Turko-Mongolic, Mongol-Tungusic, and Korean-Japanese, using lexostatistical evidence to justify it.[2]: 230–234 The inclusion of Korean and Japanese into the Altaic language family differs from the comparative works of earlier Altaicists.[3] The dictionary makes distinctions between inherited words and interlingual borrowings.
Reception
The Etymological Dictionary of the Altaic Languages, although aimed at providing further proof for the existence of the Altaic language family, received criticism from other linguists. Due to the 2,800 etymologies, it was seen as a large and important work in linguistics. It has been criticized for missing small details and requirements in its comparisons, and that the dictionary would have to need more evaluation by Stefan Georg,[4] which Starostin responded to.[5] Roy Andrew Miller, an Altaicist, praised it, saying that the "publication can only be welcomed, not only by comparative and historical linguists but by everyone interested in the early history and cultures of Greater Asia. The thousands of pages in these three volumes make available important scholarship by our Russian colleagues, much of which until recently lurked in the decent obscurity of Soviet books and periodicals always difficult if not impossible to obtain in the West..."[6]
References
- BRILL. Etymological Dictionary of the Altaic Languages (3 vols) | brill. Retrieved 12-9-2019.
https://en.wikipedia.org/wiki/Etymological_Dictionary_of_the_Altaic_Languages
 Cover of the first edition | |
| Author | Joseph Greenberg |
|---|---|
| Country | United States |
| Language | English |
| Subject | Languages of Africa |
| Published | 1963 |
| Media type | |
The Languages of Africa is a 1963 book of essays by the linguist Joseph Greenberg, in which the author sets forth a genetic classification of African languages that, with some changes, continues to be the most commonly used one today. It is an expanded and extensively revised version of his 1955 work Studies in African Linguistic Classification, which was itself a compilation of eight articles which Greenberg had published in the Southwestern Journal of Anthropology between 1949 and 1954. It was first published in 1963 as Part II of the International Journal of American Linguistics, Vol. 29, No. 1; however, its second edition of 1966, in which it was published (by Indiana University, Bloomington: Mouton & Co., The Hague) as an independent work, is more commonly cited.[citation needed]
Its author describes it as based on three fundamentals of method:
- "The sole relevance in comparison of resemblances involving both sound and meaning in specific forms."[page needed]
- "Mass comparison as against isolated comparisons between pairs of languages."[page needed]
- "Only linguistic evidence is relevant in drawing conclusions about classification."[page needed]
Innovations
Greenberg's Niger–Congo family was substantially foreshadowed by Westermann's "Western Sudanic", but he changed the subclassification, including Fulani (as West Atlantic) and the newly postulated Adamawa–Eastern, excluding Songhai, and classifying Bantu as merely a subfamily of Benue–Congo (previously termed "Semi-Bantu").
Semitic, Berber, Egyptian and Cushitic had been generally accepted as members of a "Hamito-Semitic" family, while Chadic, Fulani, "Nilo-Hamitic" and Hottentot had all been controversially proposed as members. He accepted Chadic (while changing its membership), and rejected the other three, establishing to most linguists' satisfaction that they had been classified as "Hamitic" for purely typological reasons. This demonstration also led to the rejection (by him and by linguistics as a whole) of the term Hamitic as having no coherent meaning in historical linguistics; as a result, he renamed the newly reclassified family "Afroasiatic".
Following Schapera and rejecting Meinhof, he classified Hottentot as a member of the Central Khoisan languages. To Khoisan he also added the much more northerly Hadza (Hatsa) and Sandawe.
His most revolutionary step was the postulation of the Nilo-Saharan family. This is still controversial, because so far attempts to reconstruct this family have been unsuccessful, but it holds promise and is it widely used. Prior linguists had noticed an apparent relationship between the majority of the languages, but had never formally proposed a family. These languages – the Eastern Sudanic, Central Sudanic, Kunama and Berta branches – Greenberg placed into a core group he called Chari–Nile, to which he added all the remaining unclassified languages of Africa that did not have noun classes. The distinction between Chari–Nile and the peripheral branches has since been abandoned. On a lower level, he placed "Nilo-Hamitic" firmly within Nilotic, following a suggestion of Köhler, and placed Eastern Sudanic on a firmer foundation.
Finally, he assigned the unclassified languages of the Nuba Hills of Kordofan to the Niger–Congo family, calling the result Congo–Kordofanian. The relationship has been accepted, with the exception of the "Tumtum" group, though the Kordofanian languages are no longer seen as being a primary branch, and the name 'Congo–Kordofanian' is no longer used.
Greenberg's four families became the dominant conception of African languages, though his subclassification did not fare as well. Niger−Congo and Afroasiatic are nearly universally accepted, with no significant support for Hamitic or the independence of Bantu. Nilo-Saharan is still considered provisional. Khoisan is now rejected by specialists, except as a term of convenience, though it may be retained in less specialized literature.
Classification
The book classifies Africa's languages into four stocks not presumed to be related to each other, as follows:
I. Congo–Kordofanian
- I.A Niger–Congo
- I.A.1 West Atlantic
- I.A.1.a Northern: Wolof, Serer-Sin, Fulani, Serer-Non, Konyagi, Basari, Biafada, Badyara (Pajade), Dyola, Mandyak, Balante, Banyun, Nalu, Cobiana, Cassanga, Bidyogo
- I.A.1.b Southern: Temne, Baga, Landoma, Kissi, Bulom, Limba, Gola
- I.A.2 Mande
- I.A.2.a Western
- I.A.2.a.1 Malinke, Bambara, Dyula, Mandinka, Numu, Ligbi, Huela, Vai, Kono, Koranko, Khasonke Bobo
- I.A.2.a.3 Mende, Loko, Gbandi, Loma, Kpelle (Guerze)
- I.A.2.a.4 Susu, Dyalonke
- I.A.2.a.5 Soninke, Bozo
- I.A.2.a.6 Duun, Dzuun, Jo, Seenku (Sembla), Kpan, Banka
- I.A.2.b Eastern
- I.A.2.b.1 Mano, Dan (Gio), Guro (Kweni), Mwa, Nwa, Beng, Gban, Tura (Wen), Yaure
- I.A.2.b.2 Samo, Bisa, Busa, Kyenga, Shanga
- I.A.3 Voltaic
- I.A.3.a Senoufo: Minianka, Tagba, Foro, Tagwana (Takponin), Dyimini, Nafana
- I.A.3.b.
Lobi-Dogon: Lobi, Dyan, Puguli, Gan, Gouin, Turuka, Doghosie, Doghosie-Fing, Kyan, Tara, Bwamu, Wara, Natioro,Dogon, Kulango - I.A.3.c Grusi: Awuna, Kasena, Nunuma, Lyele, Tamprusi,
Kanjaga (Bulea)(moved to group d), Degha, Siti, Kurumba (Fulse), Sisala - I.A.3.d Mossi, Dagomba, Kusasi, Nankanse, Talensi, Mamprusi, Wala, Dagari, Birifo, Namnam, Kanjaga (Bulea) (moved from group c)
- I.A.3.e Tem, Kabre, Delo, Chala
- I.A.3.f Bargu (Bariba)
- I.A.3.g Gurma, Tobote (Basari), Kasele (Chamba), Moba
- I.A.3.x Dogon[1]
- I.A.4 Kwa
- I.A.4.a Kru: Bete, Bakwe, Grebo, Bassa, De, Kru (Krawi)
- I.A.4.b Avatime, Nyangbo, Tafi, Logba, Likpe, Ahlo, Akposo, Lefana, Bowili, Akpafu, Santrokofi, Adele, Kebu, Anyimere, Ewe, Aladian, Avikam, Gwa, Kyama, Akye, Ari, Abe, Adyukru, Akan (Twi, Anyi, Baule, Guang, Metyibo, Abure), Ga, Adangme
- I.A.4.c Yoruba, Igala
- I.A.4.d Nupe, Gbari, Igbira, Gade
- I.A.4.e Bini, Ishan, Kukuruku, Sobo
- I.A.4.f Idoma, Agatu, Iyala
- I.A.4.g Ibo
- I.A.4.h Ijo
- I.A.5 Benue–Congo
- I.A.5.A Plateau
- I.A.5.A.1
- I.A.5.A.1.a Kambari, Dukawa, Dakakari, Basa, Kamuku, Reshe
- I.A.5.A.1.b Piti, Janji, Kurama, Chawai, Anaguta, Buji, Amap, Gure, Kahugu, Ribina, Butawa, Kudawa
- I.A.5.A.2 Afusare, Irigwe, Katab, Kagoro, Kaje, Kachicheri, Morwa, Jaba, Kamantan, Kadara, Koro, Afo
- I.A.5.A.3 Birom, Ganawuri (Aten)
- I.A.5.A.4 Rukuba, Ninzam, Ayu, Mada, Kaninkwom
- I.A.5.A.5 Eggon, Nungu, Yeskwa
- I.A.5.A.6 Kaleri, Pyem, Pai
- I.A.5.A.7 Yergam, Basherawa
- I.A.5.B Jukunoid: Jukun, Kentu, Nyidu, Tigong, Eregba, Mbembe, Zumper (Kutev, Mbarike), Boritsu
- I.A.5.C Cross-River
- I.A.5.C.1 Boki, Gayi (Uge), Yakoro
- I.A.5.C.2 Ibibio, Efik, Ogoni (Kana), Andoni, Akoiyang, Ododop, Korop
- I.A.5.C.3 Akunakuna, Abine, Yako, Asiga, Ekuri, Ukelle, Okpoto-Mteze, Olulomo
- I.A.5.D Bantoid: Tiv, Bitare, Batu, Ndoro, Mambila, Bute, Bantu
- I.A.6 Adamawa–Eastern
- I.A.6.A Adamawa
- I.A.6.A.1 Tula, Dadiya, Waja, Cham, Kamu
- I.A.6.A.2 Chamba, Donga, Lekon, Wom, Mumbake
- I.A.6.A.3 Daka, Taram
- I.A.6.A.4 Vere, Namshi, Kolbila, Pape, Sari, Sewe, Woko, Kotopo, Kutin, Durru
- I.A.6.A.5 Mumuye, Kumba, Gengle, Teme, Waka, Yendang, Zinna
- I.A.6.A.6 Dama, Mono, Mbere, Mundang, Yasing, Mangbei, Mbum, Kpere, Lakka, Dek
- I.A.6.A.7 Yungur, Mboi, Libo, Roba
- I.A.6.A.8 Kam
- I.A.6.A.9 Jen, Munga
- I.A.6.A.10 Longuda
- I.A.6.A.11 Fali
- I.A.6.A.12 Nimbari
- I.A.6.A.13 Bua, Nielim, Koke
- I.A.6.A.14 Masa
- I.A.6.B Eastern
- I.A.6.B.1 Gbaya, Manja, Mbaka
- I.A.6.B.2 Banda
- I.A.6.B.3 Ngbandi, Sango, Yakoma
- I.A.6.B.4 Zande, Nzakara, Barambo, Pambia
- I.A.6.B.5 Bwaka, Monjombo, Gbanziri, Mundu, Mayogo, Bangba
- I.A.6.B.6 Ndogo, Bai, Bviri, Golo, Sere, Tagbo, Feroge, Indri, Mangaya, Togoyo
- I.A.6.B.7 Amadi (Madyo, Ma)
- I.A.6.B.8 Mondunga, Mba (Bamanga)
- I.B Kordofanian
- I.B.1 Koalib: Koalib, Kanderma, Heiban, Laro, Otoro, Kawama, Shwai, Tira, Moro, Fungor
- I.B.2 Tegali: Tegali, Rashad, Tagoi, Tumale
- I.B.3 Talodi: Talodi, Lafofa, Eliri, Masakin, Tacho, Lumun, El Amira
- I.B.4 Tumtum: Tumtum, Tuleshi, Keiga, Karondi, Krongo, Miri, Kadugli, Katcha
- I.B.5 Katla: Katla, Tima
II. Nilo-Saharan
- II.A Songhai
- II.B Saharan
- II.B.a Kanuri, Kanembu
- II.B.b Teda, Daza
- II.B.c Zaghawa, Berti
- II.C Maban: Maba, Runga, Mimi of Nachtigal, Mimi of Gaudefroy-Demombynes
- II.D. Fur
- II.E. Chari–Nile
- II.E.1 Eastern Sudanic
- II.E.1.1 Nubian
- II.E.1.1.a Nile Nubian (Mahas-Fadidja and Kenuzi-Dongola)
- II.E.1.1.b Kordofanian Nubian: Dair, Dilling, Gulfan, Garko, Kadero, Kundugr
- II.E.1.1.c Midob
- II.E.1.1.d Birked
- II.E.1.2 Murle (Beir), Longarim, Didinga, Suri, Mekan, Murzu, Surma (including Tirma and Zulmanu), Masongo
- II.E.1.3 Barea
- II.E.1.4 Ingassana (Tabi)
- II.E.1.5 Nyima, Afitti
- II.E.1.6 Temein, Teis-um-Danab
- II.E.1.7 Merarit, Tama, Sungor
- II.E.1.8 Dagu of Darfur, Baygo, Sila, Dagu of Dar Dagu (Wadai), Dagu of Western Kordofan, Njalgulgule, Shatt, Liguri
- II.E.1.9 Nilotic
- II.E.1.9.a Western
- II.E.1.9.a.1 Burun
- II.E.1.9.a.2 Shilluk, Anuak, Acholi, Lango, Alur, Luo, Jur, Bor
- II.E.1.9.a.3 Dinka, Nuer
- II.E.1.9.b Eastern
- II.E.1.9.b.1 Bari, Fajulu, Kakwa, Mondari
- II.E.1.9.b.2a Jie, Dodoth, Karamojong, Teso, Topotha, Turkana
- II.E.1.9.b.2b Masai
- II.E.1.9.b.3 Southern: Nandi, Suk, Tatoga[2]
- II.E.1.10 Nyangiya, Teuso
- II.E.2 Central Sudanic
- II.E.2.1 Bongo, Baka, Morokodo, Beli, Gberi, Sara dialects (Madjinngay, Gulai, Mbai, Gamba, Kaba, Dendje, Laka), Vale, Nduka, Tana, Horo, Bagirmi, Kuka, Kenga, Disa, Bubalia
- II.E.2.2 Kreish
- II.E.2.3 Binga, Yulu, Kara [= Tar Gula]
- II.E.2.4 Moru, Avukaya, Logo, Keliko, Lugbara, Madi
- II.E.2.5 Mangbetu, Lombi, Popoi, Makere, Meje, Asua
- II.E.2.6 Mangbutu, Mamvu, Lese, Mvuba, Efe
- II.E.2.7 Lendu
- II.E.3 Berta
- II.E.4 Kunama
- II.F Koman/Coman: Komo, Ganza, Uduk, Gule, Gumuz, Mao
III. Afroasiatic
- III.A Semitic
- III.B Egyptian
- III.C Berber
- III.D Cushitic
- III.D.1 Northern Cushitic: Beja (Bedauye)
- III.D.2 Central Cushitic: Bogo (Bilin), Kamir, Khamta, Awiya, Damot, Kemant, Kayla, Quara
- III.D.3 Eastern Cushitic: Saho-Afar, Somali, Galla, Konso, Geleba, Marille, (Reshiat, Arbore), Gardula, Gidole, Gowaze, Burji, Sidamo, Darasa, Kambata, Alaba, Hadya, Tambaro, Mogogodo (added 1966)
- III.D.4 Western Cushitic: Janjero, Wolamo, Zala, Gofa, Basketo, Baditu, Haruro, Zaysse, Chara, Gimira, Benesho, Nao, Kaba, Shako, She, Maji, Kafa, Garo, Mocha, Anfillo (Mao), Shinasha, Bako, Amar, Bana, Dime, Gayi, Kerre, Tsamai, Doko, Dollo
- III.D.5 Southern Cushitic: Burungi (Mbulungu), Goroa (Fiome), Alawa (Uwassi), Iraqw, Mbugu, Sanye [= Dahalo], Ngomvia (added 1966)
- III.E Chad
- III.E.1
- III.E.1.a Hausa, Gwandara
- III.E.1.b Ngizim, Mober [= Kanuri, not Chadic], Auyokawa, Shirawa, Bede
- III.E.1.c
- III.E.1.c.i Warjawa, Afawa, Diryawa, Miyawa, Sirawa
- III.E.1.c.ii Gezawa, Sayawa, Barawa of Dass
- III.E.1.d
- III.E.1.d.i Bolewa, Karekare, Ngamo, Gerawa, Gerumawa, Kirifawa, Dera (Kanakuru), Tangale, Pia, Pero, Chongee, Maha (added 1966)
- III.E.1.d.ii Angas, Ankwe, Bwol, Chip, Dimuk, Goram, Jorto, Kwolla, Miriam, Montol, Sura, Tal, Gerka
- III.E.1.d.iii Ron
- III.E.2 Kotoko group: Logone, Ngala [= Mpade?], Buduma, Kuri, Gulfei, Affade, Shoe, Kuseri
- III.E.3 Bata–Margi group
- III.E.3.a Bachama, Demsa, Gudo, Malabu, Njei (Kobochi, Nzangi, Zany), Zumu (Jimo), Holma, Kapsiki, Baza, Hiji, Gude (Cheke), Fali of Mubi, Fali of Kiria, Fali of Jilbu, Margi, Chibak, Kilba, Sukur, Vizik, Vemgo, Woga, Tur, Bura, Pabir, Podokwo
- III.E.3.b Gabin, Hona, Tera, Jera, Hinna (Hina)
- III.E.4
- III.E.4.a Hina, Daba, Musgoi, Gauar
- III.E.4.b Gisiga, Balda, Muturua, Mofu, Matakam
- III.E.5 Gidder
- III.E.6 Mandara, Gamergu
- III.E.7 Musgu
- III.E.8 Bana, Banana (Masa), Lame, Kulung
- III.E.9
- III.E.9.a Somrai, Tumak, Ndam, Miltu, Sarwa, Gulei [= Tumak?]
- III.E.9.b Gabere, Chiri, Dormo, Nangire
- III.E.9.c Sokoro (Bedanga), Barein
- III.E.9.d Modgel
- III.E.9.e Tuburi
- III.E.9.f Mubi, Karbo, (added 1966: Jegu, Jonkor, Wadai-Birgid)
IV Khoisan
- IV.A South African Khoisan
- IV.A.1 Northern South African Khoisan
- IV.A.2 Central South African Khoisan
- IV.A.3 Southern South African Khoisan
- IV.B Sandawe
- IV.C Hatsa
Bibliography
- Greenberg, Joseph H. (1963) The Languages of Africa. International journal of American linguistics, 29, 1, part 2.
- Greenberg, Joseph H. (1966) The Languages of Africa (2nd ed. with additions and corrections). Bloomington: Indiana University.
References
- The text says this is not a subgroup of Eastern, suggesting that this should rather be II.E.1.9.c.
https://en.wikipedia.org/wiki/The_Languages_of_Africa
No comments:
Post a Comment